

JavaScriptでルールを書けるテキスト/Markdownの校正ツール textlint を作った
azu/textlint

textlint というテキスト(plain textとMarkdown)の校正をするためのコマンドラインツールを書きました。textlintはNode.jsで書かれていて、Node.jsモジュールとしての利用することもできます。
一番の特徴は校正するルールをJavaScriptで書くことで拡張可能な作りになっています。
The pluggable linting tool for text(plain text and markdown).
逆にデフォルトではルールはサンプル扱いのno-todoというTODOが含まれてることを検知するルールしか今のところ入れていません。
デフォルトでルールが用意されていて、それの設定を変更することでLintする場合はRedPenなどがお勧めです。
使い方
たとえば、自分が書いた技術用語のチェックをするルール(WEB+DB PRESS表記ルールベース)を使いたい場合は以下のようにして利用できます。
npm install textlint -g
npm install spellcheck-tech-word-textlint-rule --save-dev
という感じでtextlint本体とルールはnpmでも公開してるので、npmでいれて以下のように--rulesdirというオプションでルールファイルがあるディレクトリを指定すれば、そのルールファイルが読み込んで実行できます。
textlint --rulesdir ./node_modules/spellcheck-tech-word-textlint-rule file.md
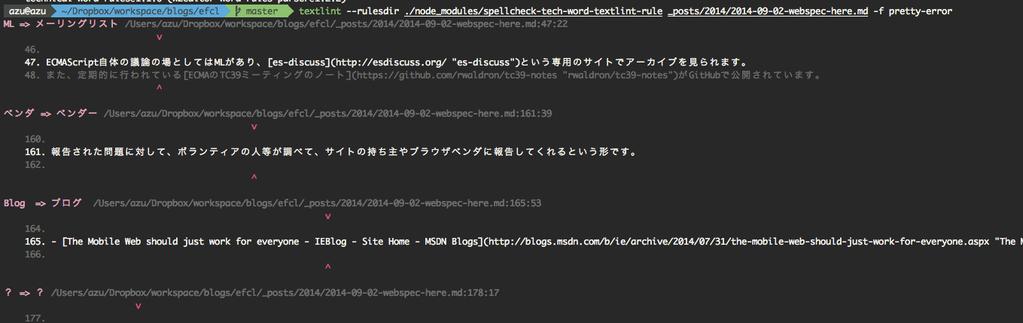
textlint --rulesdir A/ --rulesdir B/ という複数のディレクトリも指定可能です。
細かいコマンドラインオプションは-hで確認出来ます。
$ textlint -h
textlint [options] file.md [file.txt] [dir]
Options:
-h, --help Show help.
--rulesdir [path::String] Set rules from this directory and set all default rules to off.
-f, --format String Use a specific output format. - default: stylish
-v, --version Outputs the version number.
--ext [String] Specify text file extensions.
--no-color Enable color in piped output.
-o, --output-file path::String Enable report to be written to a file.
--quiet Report errors only. - default: false
--stdin Lint code provided on <STDIN>. - default: false
formatters
Lintした結果の出力方法はいろいろ用意してあって “stylish” (デフォルト), “compact”, “checkstyle”, “jslint-xml”, “junit”, “tap”, “pretty-error”が利用できます。(スクリーンショットとかは”pretty-error”ですが、 East Asian Widthの問題でまだイマイチ不安定…)
-o と合わせれば、ファイルとして出力できます。(checkstyleとかはWebStormがESLint連携で使ったりしてるっぽいです)
これはESLintと互換性のあるformattersの実装になっているため、ESLintで使われてるformattersをそのまま利用しました。
また、pluggable linting toolでわかるかもしれませんが textlint 自体が全体的にESLintを真似て作ってあります。(オプションとか一部意味が変わったり省いていますが)
ルールの作り方
textlint の最大の特徴であるルールをJavaScriptで書ける点についてです。
正直、正確な校正ツールを求めるならば、自然言語をちゃんと解釈してMarkdownもサポートしてるRedPenとかを利用したほうが質がいいと思います。 textlintはあくまでも自分でルール作りが手軽に出来るようにするのが目的です。
ルールの書き方もESLintと同じなので、ESLintのドキュメントも見てもらうといいかもしれません。
- ESLint - Working with Rules
- Maintaining JavaScript Code Quality with ESLint | PayPal Engineering Blog
- コードのバグはコードで見つけよう!|サイバーエージェント 公式エンジニアブログ
ESLintはJavaScriptをASTにしてLintをしますが、textlintはテキストやMarkdownをASTにしてLintをします。
MarkdownのASTはCommonMarkを元にして正規化したものを、plain textのASTはそれっぽくパースして、両方共TxtNode interfaceというものに則った形になります。(typeの種類に差がありますが、文字列や改行などは共通しています)
MarkdownのASTは安定したものはまだないので、wooorm/mdastというプロジェクトがrange/locationをサポートしてくれたらこっちに移行するかもしれません。 ただし、その場合もできるだけルールの互換性はとるようにするつもりです。
ルールの作成方法に話を戻すと、基本的な作り方についてはcreate-rules.mdにかいてあります。
ルールの実装について
create-rules.md に同様のことが書いてあります
ルールとなるJavaScriptはひとつの関数をexportsします。
その関数にはutilsなど入ったRuleContextというもとが渡されます。
このRuleContextには、Nodeから元ファイルのテキストを取得するcontext.getSourceなどがあります。
またNode自体はTxtNode interfaceに沿ったtypeやlocなどの情報が入っています。
(まだparentなどが未完です => 実装 textlint 1.4 パーサの安定化、ルールの自由度の改善をして現実的に使えるLintツールへ | Web Scratch)
/**
* @param {RuleContext} context
*/
module.exports = function (context) {
var exports = {};
// root object
exports[context.Syntax.Document] = function (node) {
};
exports[context.Syntax.Paragraph] = function (node) {
};
// 文字列のNodeごとにこの関数がよばれる
exports[context.Syntax.Str] = function (node) {
// そのNodeの文字列(内容)をみてよくないと思ったら`context.report`で報告する
var text = context.getSource(node);
if(/found wrong use-case/.test(text)){
// report error
context.report(node, new context.RuleError("found wrong"));
}
};
exports[context.Syntax.Break] = function (node) {
};
return exports;
};
たとえば、no-todoというルールを作りたいときはno-todo.jsというファイル名で以下のようにルールを書きます。(ファイル名 == ルールIDなので揃える)
このルールは- [ ]やtodo:のような文字列を見つけたらエラーにするということを目的にします。
context.Syntax.Str というのは普通の文字列がやってくるので(パラグラフやリストの中、ラベルなどのタイミング)、それを正規表現で/todo:/i.test(text)という感じでチェックするだけですね。
また、Markdownは- itemや* itemといったリスト記法があるので、それらのリストアイテムが来た時に呼びたいチェック関数はcontext.Syntax.ListItemに定義しておけば問題ありません。
Nodeにどのようなtypeがあるかはunion-syntax.jsを参照して下さい。
ただし、plain textにはListItemというタイプはないので、その場合は呼ばれることはありません。
ファイル種類ごとにどのようなtypeがあるかは以下に書かれています。
"use strict"
/**
* @param {RuleContext} context
*/
module.exports = function (context) {
var exports = {};
// When `node`'s type is `Str` come, call this callback.
/*
e.g.)
# Header
this is Str.
Todo: quick fix this.
*/
// `Str` is "this is Str." and "Todo: quick fix this.", so called this callback twice.
exports[context.Syntax.Str] = function (node) {
// get text from node
var text = context.getSource(node);
// does text contain "todo:"?
if (/todo:/i.test(text)) {
context.report(node, new context.RuleError("found Todo: " + text));
}
};
// When `node`'s type is `ListItem` come, call this callback.
/*
e.g.)
# Header
- list 1
- [ ] todo
*/
// `List` is "- list 1" and - [ ] todo", so called this callback twice.
exports[context.Syntax.ListItem] = function (node) {
var text = context.getSource(node);
if (/\[\s*?\]\s/i.test(text)) {
context.report(node, new context.RuleError("found Todo: " + text));
}
};
return exports;
};
こうして作ったルールをnpmやGitHubなどに公開して、先ほど紹介した--rulesdirなどで指定すればすぐに利用できます。
公開するときにtextlintというキーワードをつけておけば発見しやすいのでつけておくといいかもしれません。
実際に作った技術用語のLint(このルールはWEB+DB PRESS用語統一ルール等を使った技術用語のLintをするCodeMirrorアドオンを書いた | Web Scratchと同じやつです)
textlintのモチベーション
spellcheck-tech-wordのようなルールでチェックするためのコマンドラインツールとNode.jsモジュールがなかったので作ったというのが始まりですが、 実際にMarkdownなどのテキストやJSONの中にあるテキストをLintするためには、それ専用のものを書く必要があって不毛な感じがしました。(ルール自体に汎用性がない)
なので、textlintが特定のフォーマットをパースしたり面倒なところをやって、ルールはどのフォーマットが来るかをあまり気にしないで書けるようにするのが目的です。
書いたあとに気づきましたが、SCG: TextLintというプロジェクトがやってることがとても似ていると思います。(名前も同じだった…)

via Natural Language Checking with Program Checking Tools
まだ正確なルールを書くにはちょっと必要なプロパティがたりてないですが、正規表現でざっとエラーチェックするみたいなことがだいぶ簡単に書けるようになってると思います。
Contributingも歓迎しています!
追記: textlint 1.4 パーサの安定化、ルールの自由度の改善をして現実的に使えるLintツールへ | Web Scratch
基本的な思想やコードの一部をESLintプロジェクトのMITライセンスのものを利用しています。ESLintに感謝を
お知らせ欄
JavaScript Primerの書籍版がAmazonで購入できます。
JavaScriptに関する最新情報は週一でJSer.infoを更新しています。
GitHub Sponsorsでの支援を募集しています。