

jser/jser.github.ioの記事をpull request時にLintする仕組み
このブログやJSer.infoはJekyllを使って動いているのですが、 どちらも記事を書くときはMarkdownを使って書かれています。
最近になって、Markdownで書いた技術用語の表記などをLintする仕組みを追加して、pull requestした際にLint結果がinvalidなら修正を促す(主に自分に対して)レビューコメントが書き込まれるHoundCIみたいな仕組みを追加しました。
追記(2016-06-18): 同じ趣旨の別記事を書きました。こちらの方が分かりやすいと思います。
記事のLint
MarkdownなのでLintingにはtextlintを使いました。
また、JSer.infoは記事の書式が特殊なので、それ用のtextlintルールを書いて使っています。
といっても基本的にはazu/spellcheck-tech-word-textlint-ruleをベースにして無視するルールを追加したspellcheck-post.jsを作って使っています。
// LICENSE : MIT
"use strict";
var RuleHelper = require("textlint-rule-helper").RuleHelper;
var spellCheck = require("spellcheck-technical-word").spellCheckText;
var ContributingLink = '[Contributing Guide](https://github.com/jser/jser.github.io/blob/master/CONTRIBUTING.md)';
/**
* @param {RuleContext} context
*/
module.exports = function (context) {
var helper = new RuleHelper(context);
var exports = {};
var Syntax = context.Syntax;
// HTMLの中身は無視する
var isCurrentHTMLBlock = false;
exports[context.Syntax.Html] = function (node) {
isCurrentHTMLBlock = true;
};
// ---- <h1 class="site-genre">ヘッドライン</h1> きたらリセット
exports[context.Syntax.HorizontalRule] = function (node) {
isCurrentHTMLBlock = false;
};
// 次のParagraphがきたらHTMLブロックは終わった事にする
exports[context.Syntax.Paragraph] = function (node) {
isCurrentHTMLBlock = false;
};
exports[context.Syntax.Str] = function (node) {
if (isCurrentHTMLBlock) {
return;
}
// Headerは自動でサイトのタイトルを使うので無視する
if (helper.isChildNode(node, [Syntax.Link, Syntax.Image, Syntax.BlockQuote, Syntax.Header])) {
return;
}
var text = context.getSource(node);
var results = spellCheck(text);
results.forEach(function (/*SpellCheckResult*/result) {
// line, column
context.report(node, new context.RuleError(result.actual + " => " + result.expected + "\n" + ContributingLink, {
line: result.paddingLine,
column: result.paddingColumn
}));
});
};
return exports;
};
- azu/technical-word-rules 辞書本体
- azu/spellcheck-technical-word 上記の辞書を使ってチェックする関数
"scripts": {
"postinstall": "bower-installer",
"lint:spell": "textlint --rulesdir test/rules -f pretty-error"
},
という感じでnpm run-scriptを定義してあるので、
$ npm run lint:spell -- path/to/file.md
とすることで記事をLintすることができるようになりました。
Lint結果をコメント
これで記事のLint自体はでるようになりましたが、単純にTravis CIでテストしてパスするかだと何が間違ってるかをTravis CIに見に行く必要があります。
jser/jser.infoの記事の元データの方はほぼ自分しか更新しないので、Travis CIで辞書Lintがパスするかどうかのテストしてますが、記事のMarkdownファイルがあるjser.github.ioは自分以外もpull requestで更新がきたりするので、テストでパスするかどうかだとちょっと不親切です。
- JSer.info 200 回目記念イベント (記事の元データうんぬんはこちら参照)
というのも、使ってる辞書のLintはそこまで正確ではないので、Warning的な扱いがちょうどいいと思ってます(最悪無視してもいいし、辞書の方を直したほうがいい時も多い)
なので、jser.github.ioの方はLintした結果をレビューコメントとして書き込むようになってます。
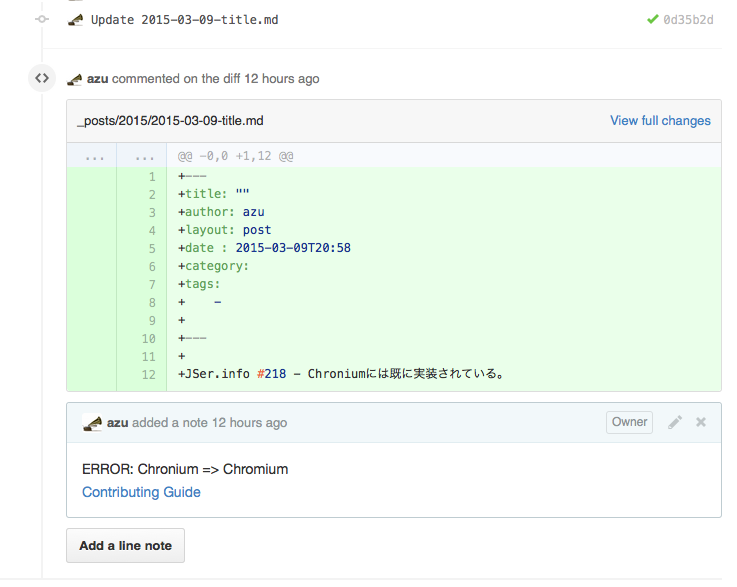
pull request時にしかこのLintは動かないので、最近記事を書くときはWIPでpull requestしながら記事を書いています。
[WIP] 2015-03-09のJS by azu · Pull Request #52 · jser/jser.github.io みたいな感じなので、途中でヘッドラインのオススメとかあればコメントくれれば反映されるかもしれません。
TraviCI -> Lint -> レビューコメント
これはpacksaddle/ruby-saddlerを使ってやっています。
Saddlerはcheckstyle形式のLint結果を渡すと、Travis CIやCircle CIからレビューコメントとして書き込んでくれるコマンドラインツールです。
基本的には以下でやっている書かれていることをやっているだけです。
TravisCIからPull Request時にコメントするためにGitHubのtokenを取得して、travis.ymlに追加します。
travis encrypt -r jser/jser.github.io GITHUB_ACCESS_TOKEN=b95xasdasx3bxsadsdadsaxx --add
travis-spellcheck.shという感じのスクリプトを作って、textlintは$(npm bin)/textlint --rulesdir test/rules -f checkstyle という感じでcheckstyle形式でも出力できるので、それをSaddlerに渡す感じです。
そのままだとファイル全体のLintの結果が含まれるので、実際にコミットの差分だけに絞りたい場合はpacksaddle/ruby-checkstyle_filter-gitをパイプするとできます。
使ったツール
お知らせ欄
JavaScript Primerの書籍版がAmazonで購入できます。
JavaScriptに関する最新情報は週一でJSer.infoを更新しています。
GitHub Sponsorsでの支援を募集しています。