

ローカルのPDFを全文検索するクライアント/サーバ/Electronアプリを書いた
ローカルにあるPDFを全部検索して、その結果を一覧したいことがあります。 例えば、今、js-primerという書籍を書いていて、ある用語が他の書籍ではどんな扱い/用語になっているのかを調べたいことがよくありました。
この手のアプリとしては論文管理のPapers for Macなどがありますが、検索したいだけなのに色々な機能がついていてまた、とりあえず作ってみることにしました。
searchiveというプロジェクト名にしてPDFからテキストを取り出す所やフロントエンドのElectronアプリ、PDFからテキストを取り出すのはブラウザでやるには遅いので、そこをサーバ側でやってくれる仕組みを作りました。
大体100冊ぐらいをインデックスに入れて検索していますが、数百ms以内に検索結果が出てるので意外と動くようです。
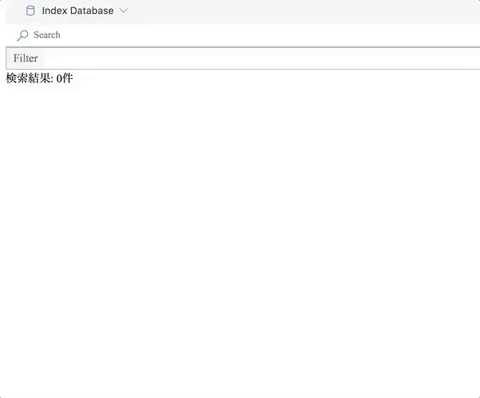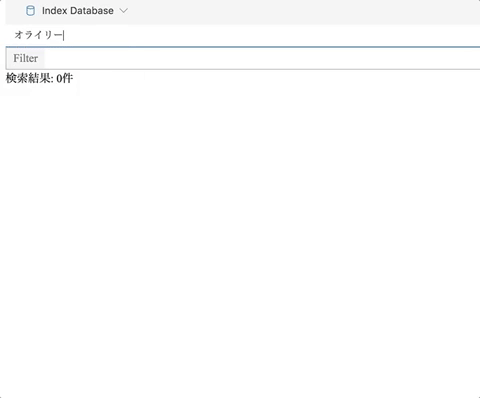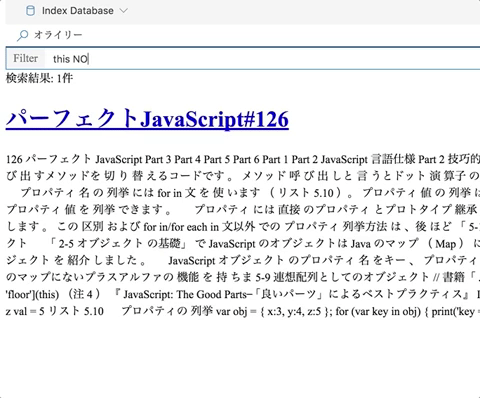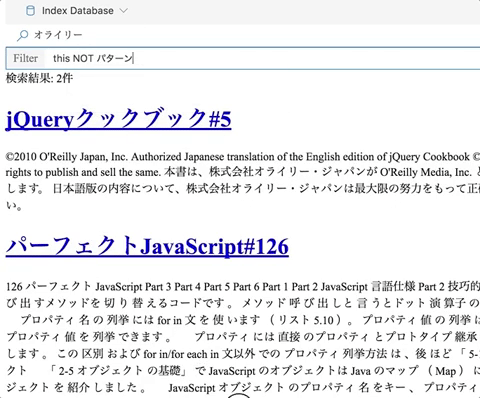
インストール
Release pageからElectronアプリをダウンロードしてインストール出来ます。Electronアプリにはサーバの実装も入ってるので、アプリを入れるだけで動きます。
- Latest Releaseからダウンロードしてインストール
- 署名してないので、右クリックの”開く”からじゃないと怒られる
AppVeyorなどのCIの設定が面倒だったので、Mac版のバイナリしか置いていませんが、searchive-appをビルドすればどのOSでも動くと思います。またはPR歓迎です。
使い方
起動したら最初にPDFのインデックスを作る必要があります。
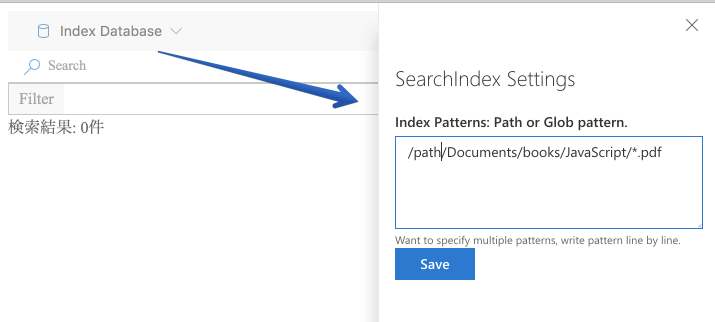
メニューから設定を開くと、インデックスしたいファイルの場所をglobで指定できます。
保存するとPDFからテキストを取り出したindex.jsonを作り出してくれます。(とても重いので放置しておくといいです)
ローディングバーが消えて終わったら後は検索するだけです。 検索結果をフィルターすることができるので、大雑把な検索をしてからフィルターする使い方を想定しています。(検索の単位はPDFのページ)
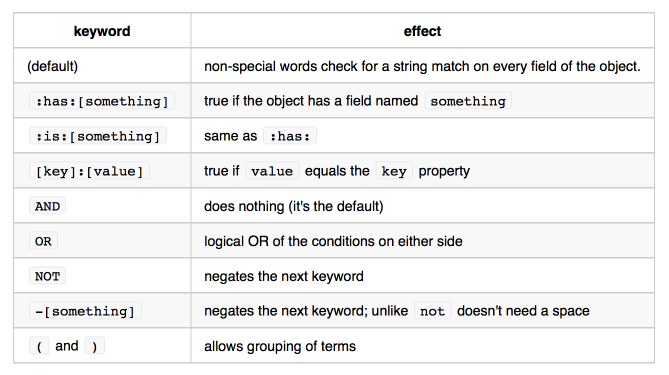
検索演算子はGitHubみたいなものが使えます。 ライブラリとしてはsearch-query-testerを使っています。
作り方
searchiveはmonorepoのプロジェクトになっていて、細かい部品を独立したライブラリとして作っています。 それらを組み合わせてsearchive-appというアプリが動いています。
それぞれの部品を順番に紹介していきます。
pdf-to-json 
pdf.jsを使ってPDFからテキストを取り出してJSONにしてくれるライブラリです。ページごとのテキストをJSONにまとめてくれます。 実際にはpdf.jsのnpm版であるpdfjs-distを使います。
pdf.jsは使いにくいライブラリ(というアプリに近い)なので、日本語などもちゃんと扱えるようにするのは工夫が必要です。
cmapsというファイルをちゃんと読めないと日本語などが扱えません。 Node.jsで扱う公式のオプションはないので、テストコードを読んでURLをfsで代替するモック実装を使って読み込むことができました。
searchive-client 
searchiveの検索やインデックへの書き込みを扱う抽象レイヤーです。fsやブラウザAPIにも依存してないクリーンなJavaScriptとして動作する層です。
searchive-create-index 
searchive-clientとpdf-to-jsonを使って、実際にインデックファイルを作るライブラリでうs。
ファイルを読み込んだり、書き込んだりするのでNode.jsに依存しています。
searchive-cli 
インデックを作ったり、実際に検索できるCLIです。
searchive-clientやsearchive-create-indexが実装の殆どを持っているため数行ぐらいしかないCLIです。monorepoだとこういう切り離しがし易いのもメリットです。
テスト用に使ったりできます。
searchive-server 
Electronアプリはmain(Node.js)とrenderer(ブラウザ)のプロセスを両方持っていますが、こちらはNode.js側の実装です。
searchive-create-indexを使ってインデックス作るWeb APIや、インデックを検索して結果を返すWeb APIを実装しています。
REST APIの実装するサーバにはrestifyを使っています。
また、インデックスを作る処理は時間がかかるためREST APIでは不向きでした。
そこでWeb Socketを使ったAPIを実装して、クライアント側とはWebSocketで進捗をやり取りしています。
サーバ側のWebSocketsはwsを使い、クライアント側はブラウザネイティブのWebSocketを使っています。
searchive-web-api-interface | 
主にWebSocketが原因でできたパッケージです。 WebSocketはReduxとかのActionみたいなコマンドをやり取りする必要があります。 それらの定義はサーバとクライアントどちらも共有したいので、インターフェイスだけを定義したパッケージを定義してサーバとクライアントではこれを使っています。
サーバ側に定義してしまうと、クライアントがサーバに依存するという問題が起きてしまうための回避策です。
searchive-app
最後にElectronで書かれたアプリです。
Electronはmain(Node.js)とrenderer(ブラウザ)の両方を持っているので、mainでsearchive-serverのサーバを動かして、rendererからAPIを叩いて使っています。
Electronのセットアップは毎回苦戦するので、今回はElectron版create-react-appのようなelectron-webpackを使っています。
これでyarn run devするだけで開発が始めらます。mainのソースが変わった場合はアプリが起動し直され、rendererの場合はHot Reloadingができる構成なので、面倒なwebpackを触れなくてよくて便利です。
TypeScriptの対応もAdd-ons · electron-webpackを入れるだけで解決するので楽でした。
一方問題もあって、webpack-dev-serverを開発中は使って、buildした場合はhtmlになるので、file:///だと特権で動く処理がdevelopment中は動かないことがあります。(webviewの中でfileなコンテンツを表示するなどがhttpのページ上ではできない)
次の記事でも同様の構成について触れています。
ViewにはReactを使っていて、UIコンポーネントとしてMSのOffice UI Fabricを使っています。Office UI Fabricはこういうアプリを作るときに便利なメニューやコンテキストメニュー、パネルなどがあるのでよく使ってます。
State管理には、Alminを使っています。 基本的にやりたいことは次のようなことだけでした。
- (APIを叩いて)検索
- (WebSocketを繋いで)インデックスを更新
- フィルターを更新
- 設定パネルを開く/閉じる
Alminでは、やりたいこと(ユースケース)を1ファイル1ユースケースで書いていきます。
なので、このアプリでは次のようなユースケースを書きました。
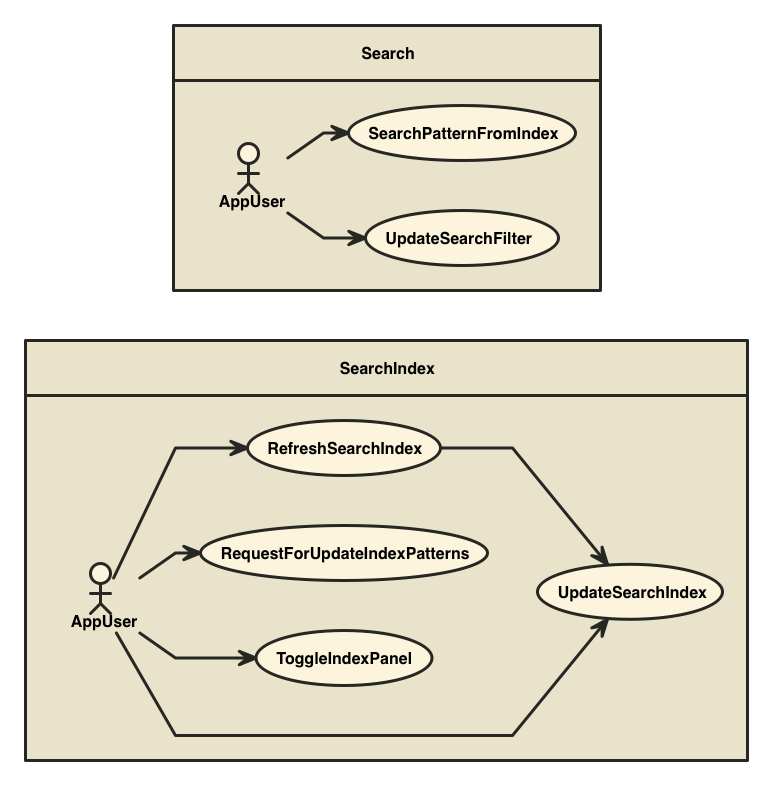
https://github.com/almin/almin-usecase-map-generatorでユースケース図を生成
このアプリではドメインとかそこまでちゃんとやっても旨味がない気がしたので、UseCaseでイベントをdispatchして、Storeでイベントを受け取ってStateを更新する感じにしました。 Reduxでよく見るような形になってると思います。

後は、almin-react-containerを使えば、AlminのStoreとReactのViewが自動で繋がるので、Stateが更新されたViewを更新するだけです。
TODO
- Electronのmainプロセスで重たい処理をすると、UIも固まるのでどうにかしたい
- インデックスを作る処理が重たい
- electron-webpackがdev serverを立てる制限で検索結果に実際にpdfを表示するプレビューがでてきてないのでどうにかしたい
- PDF以外も原理的に対応できるのでテキストファイルも合わせて検索したい
おわり
ローカルのPDFを全文検索するsearchive-appの紹介とそのプロジェクト構造の解説をしました。
最初はelasticlunr.jsとかを使った全文検索を実装していたのですが、単純にJSONを保存してその中身を単純にマッチしたほうが早かったので変更した経緯とかがあります。
勢いで自分用に書いたところが多いので、PRやIssueとかあったらよろしくお願いします。
お知らせ欄
JavaScript Primerの書籍版がAmazonで購入できます。
JavaScriptに関する最新情報は週一でJSer.infoを更新しています。
GitHub Sponsorsでの支援を募集しています。