

textlint 5.0.0で非同期処理に対応、kuromoji.jsで校正、テキストの統計処理
textlint 5.0.0をリリースしました。 非同期対応のためAPIを変更したのがメインの理由です。
textlint自体については以下の記事で紹介しています。
前回は4.0リリースの時に書いたので、4.0から5.0での変更点に紹介していきます。
変更点
Breaking Change
大きな変更点として全てのLint APIが非同期処理となりました。 そのため、以下のメソッドはそれぞれPromiseを返すようになっています。
textlintツール利用者には影響なくて、textlintをモジュールとして使ってる人のみに影響します。
TextLintCore#LintFileTextLintCore#LintTextTextLintEngine#executeOnFilesTextLintEngine#executeOnTextcli#execute
var textlint = new TextLintCore();
textlint.lintMarkdown("text").then(result => {
// result.messages
});
新しい機能
Warning #44
4.1.0でルールをエラーではなく警告として出すことが出来るようになりました。
以下のようにseverityオプションを設定することで、LintにかかるものがあってもexitStatusが0として終わったり、formatterで警告として出してくるようになります。
{
"rules": {
"no-todo": {
"severity" : "warning"
}
}
}
Processor Plugin #37
4.3.0でProcessor Pluginをサポートしました。Processor Pluginはプラグインで任意の拡張子に対応出来るような仕組みのことです。
textlint本体のMarkdown対応などもProcessor Pluginとして実装されています。
- textlint/textlint-plugin-text built-in
- textlint/textlint-plugin-markdown built-in
- textlint/textlint-plugin-html optional
自分で任意のフォーマットに対するパーサを書いてTxtNodeからなるASTを作れば、textlintはそれを扱えるようになっています。
実際に作るとtypeがPlugin間で固定されていたりするので、その辺はIssueなどを立てて頂けると対応できます。
textlint本体からは特定のフォーマットに依存するような処理は外部モジュールやプラグイン、ルールとして実装してあります。
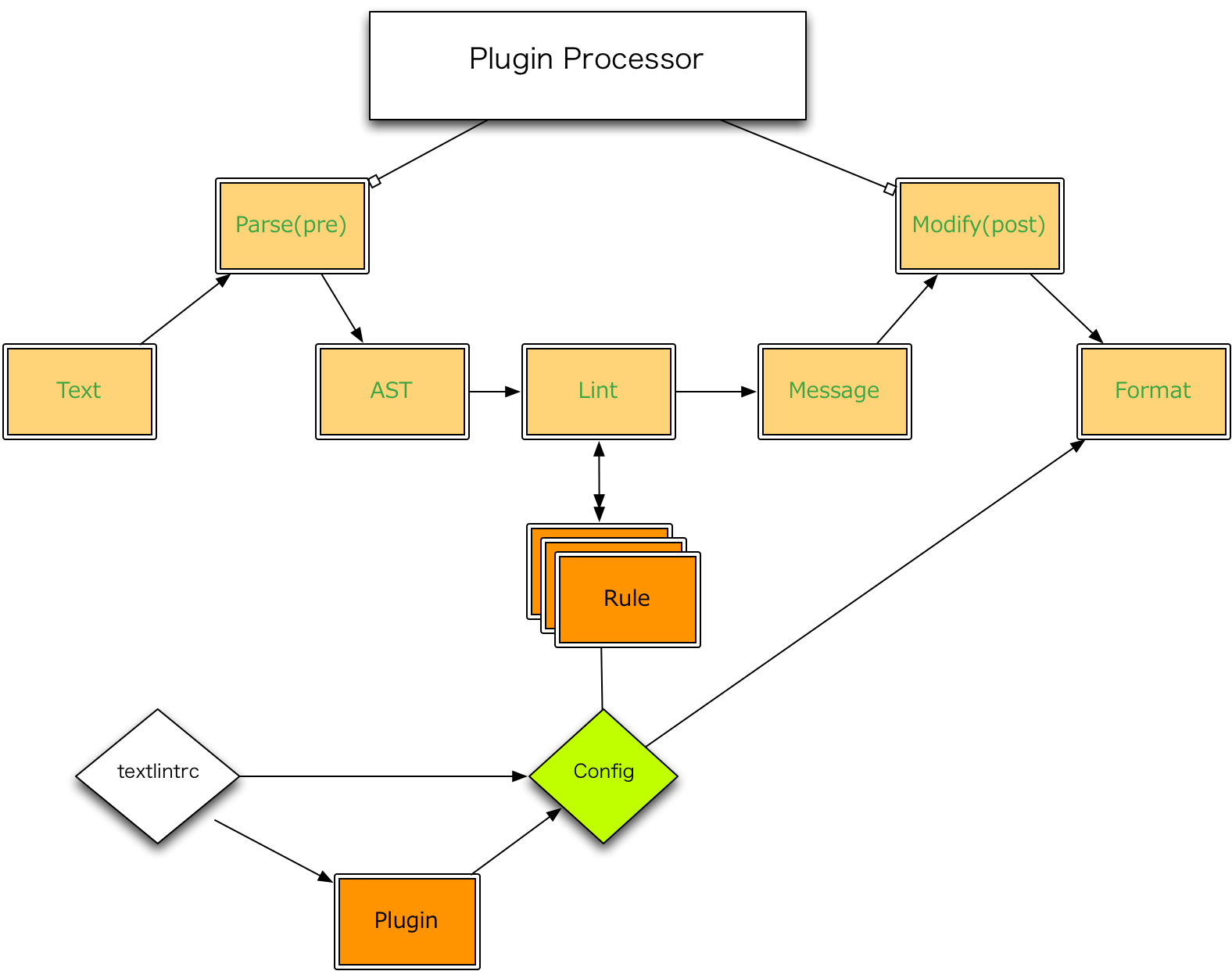
そのためTxtNodeやTextLintMessageといったインタフェースだけを決めて、具体的な処理は外に移譲しています。
この辺を上手く使ってテキストの統計データを出せるtextstatを作ったりしています。
ルール毎のパフォーマンス表示
4.6.0でTIMING=1という環境変数を設定して実行すると、それぞれのルールにかかってる処理時間をだせるようになりました。
(ESLintと全く同じ実装なので、非同期のルールに対応できてない…)
$ TIMING=1 textlint README.md
Rule | Time (ms) | Relative
:-------------------------------|----------:|--------:
spellcheck-tech-word | 124.277 | 70.7%
prh | 18.419 | 10.5%
no-mix-dearu-desumasu | 13.965 | 7.9%
max-ten | 13.246 | 7.5%
no-start-duplicated-conjunction | 5.911 | 3.4%
context#getFilePathの追加
4.7.0でcontext#getFilePathというAPIを追加しました。
これは処理しているファイルパスを返します。(標準入力を対象した場合はnullを返します)
以下のようにしてファイルパスを取得することができます。
import fs from "fs";
import fileSize from "filesize";
export default function (context) {
let { Syntax, getFilePath, report } = context;
return {
[Syntax.Document](node){
// ファイルパスを取得
let filePath = getFilePath();
try {
var stats = fs.statSync(filePath);
// ファイルサイズを取る Kb
var fileSizeInBytes = stats["size"];
} catch (e_e) {
}
}
}
}
ルール内で非同期処理が可能に
今まではルール内で同期的な処理しか書けませんでしたが、 5.0.0からはpromiseオブジェクトを返すとそのpromiseが解決できるまで結果を待つようになっています。
以下のようにPromiseを返すことで、非同期処理をルール中に書くことができます。 (同期処理は今まででと何も変わらない)
export default function (context) {
return {
[Syntax.Str](node){
// textlint wait for resolved the promise.
return new Promise((resolve, reject) => {
// async task
});
}
}
}
ルール中で返したPromiseオブジェクトが全てresolveすると処理が終わったと判断して、結果を出力するようになっています。
一つでもRejectedとなったPromiseがある場合に失敗したと判断してエラーを出します。(Promise.allをしているだけです)
非同期の使い道
ほぼ同じ機構を持つESLintが非同期対応してないことからも分かりますが、普通にLintする場合は非同期APIがなくても問題ないです。
textlintはESLintと違って自然言語を扱うことが多いです。 自然言語の場合は形態素解析をするなど重たい処理があったり、他の言語で書かれた外部のプロセスに処理を投げられると便利です。
そのため、textlintからREST APIを通信してLintができるようにするための変更です。
textlintのruleでYahooの校正API叩くのって悪手かなー。個人で使う分には問題無さそうだけども。
— もろみざとけいた (@kta_moromii) November 3, 2015追記: できたそうです => CircleCI - 継続的インテグレーションで実現するWebメディアの執筆フロー - Qiita
また、kuromoji.jsのように辞書の非同期ロードが必要なものへ対応したかったのも理由の一つです。
実際に非同期処理を使ったルールとしてazu/textlint-rule-no-doubled-joshiがあります。
textlint-rule-no-doubled-joshiは1センテンス中に同じ助詞が連続して使われてないかをチェックするルールです。
材料不足で代替素材で製品を作った
を例にすると”で”という助詞が連続している部分を検出できます。
RedPenの_DoubledJoshi_と大体同じですが、デフォルトでは”の”、“を”は例外的に除外したり緩めの設定です。
オプションで{"strict":true}とすれば少し厳しく判定するようになっています。
実際に使ってみると案外気づけなかった部分が分かります。 Lint結果に従いリファクタリングしていくとセンテンスは短くなる傾向があります。
1センテンスを短く分解する手法については以下のスライドが参考になります。
この記事もno-doubled-joshiでチェックしながら書かれています。 ただ、適当に書くと色々指摘されるので、気軽に書きたいブログとかだとやかましいかもしれないですね。
ルールの仕組み
このルールはsentence-splitterを使ってパラグラフをセンテンスに分解し、kuromoji.jsを使ってセンテンスを形態素解析して品詞をチェックすることでチェックしています。
kuromoji.jsを直接使うと同時に辞書を読み込もうとして、読み込みが終わらない問題を作りやすいので、azu/kuromojinというkuromoji.jsのPromiseラッパを作りました。
同時に初期化(辞書を読み込み)しても大丈夫なようにロックと、一度読み込んだら次からキャッシュを使うようにするシンプルなラッパーです。
textlint-rule-no-doubled-joshiでは以下のように、テキストをセンテンスに分解して、センテンスをさらにkuromoji.jsで形態素解析しています。
そうして取れたtokenの品詞を見ていき、助詞が連続してないかをチェックするような仕組みになっています。
import {getTokenizer} from "kuromojin";
import splitSentences, {Syntax as SentenceSyntax} from "sentence-splitter";
export default function (context) {
let {Syntax, report, getSource, RuleError} = context;
return {
// TODO: 本来はParagraphでやるべき
// text `code` text のようなものが対象にできてない
[Syntax.Str](node){
let text = getSource(node);
// テキストをセンテンスに分解
let sentences = splitSentences(text).filter(node => {
return node.type === SentenceSyntax.Sentence;
});
// 非同期でkuromoji.jsの初期化&ロック&キャッシュ
return getTokenizer().then(tokenizer => {
const checkSentence = (sentence) => {
// センテンス毎のtokensを取り出してチェック処理
let tokens = tokenizer.tokenizeForSentence(sentence.raw);
};
sentences.forEach(checkSentence);
});
}
}
};
ルール間で初期化コストを共有できるので、azu/kuromojin経由で使っておくと楽なのかもしれません(もっといい方法がありそうならIssueとか立てて下さい)
その他
Atomプラグインであるlinter-textlintもtextlint 5.0.0に対応しています。
Atomで書きながらチェック出来るのでかなり便利です。

Windowsでの導入方法の例 (特にOS依存はないので、どの環境も普通にnpm installしてプロジェクトを開けば使えます)
gulpから使う場合はgulp-textlintなどもあるので、こちらの方を利用するといい気がします。
textstat
textstatというtextlintの上で動くテキスト統計処理ツールも公開しています。 (Wordの文字数カウントとかそういう感じのものです)
基本的にルールの書き方や設定ファイルの書き方も同じですが、こちらはデフォルトで幾つかルールを持っています。 (言語が関係ないファイルサイズや行数などの統計ルール)
日本語向けのルールを思いつきで書いてるtextstat-plugin-jaというプラグインも公開しているので、以下のような手順で使うと簡単にファイルのテキスト統計情報が出せます。
$ npm install textstat-plugin-ja textstat -g
$ textstat --plugin ja _posts/2015/2015-11-19-textlint5.0.0.md
┌──────────────────────┬────────────────────────────────────────────────────────────┐
│ filePath │ _posts/2015/2015-11-19-textlint5.0.0.md │
├──────────────────────┼────────────────────────────────────────────────────────────┤
│ fileSize │ 26.07 kB │
├──────────────────────┼────────────────────────────────────────────────────────────┤
│ number of characters │ 15782 │
├──────────────────────┼────────────────────────────────────────────────────────────┤
│ number of Lines │ 322 │
├──────────────────────┼────────────────────────────────────────────────────────────┤
│ number of Images │ 2 │
├──────────────────────┼────────────────────────────────────────────────────────────┤
│ number of Links │ 43 │
├──────────────────────┼────────────────────────────────────────────────────────────┤
│ number of List Items │ 18 │
├──────────────────────┼────────────────────────────────────────────────────────────┤
│ number of Paragraphs │ 75 │
├──────────────────────┼────────────────────────────────────────────────────────────┤
│ number of sentences │ 172 │
├──────────────────────┼────────────────────────────────────────────────────────────┤
│ share of code │ 48% │
├──────────────────────┼────────────────────────────────────────────────────────────┤
│ 文字種 │ │
├──────────────────────┼────────────────────────────────────────────────────────────┤
│ ひらがな │ 36% │
├──────────────────────┼────────────────────────────────────────────────────────────┤
│ カタカナ │ 9% │
├──────────────────────┼────────────────────────────────────────────────────────────┤
│ 漢字 │ 16% │
├──────────────────────┼────────────────────────────────────────────────────────────┤
│ アルファベット │ 29% │
├──────────────────────┼────────────────────────────────────────────────────────────┤
│ 日本文の読みやすさ │ 54.7 │
├──────────────────────┼────────────────────────────────────────────────────────────┤
│ │ 読みやすさの偏差値(平均50、標準偏差10、高いほど読みやすい) │
└──────────────────────┴────────────────────────────────────────────────────────────┘
textstatもルールはJavaScriptで簡単に書けるので、気になった部分を数値として出してみると面白いかもしれません。
今後
形態素解析を使ったルールも書けるようになったので、初期にやりたかった事は大体できた気がします。
ルールもある程度増えてきたので、逆にどうやって使い始めればいいかみたいなドキュメントが不足してるのでその辺を追加する予定です。
日本語向けのルールばかりなので、普通にブログでオススメ設定を書くみたいのでも良さそうな気はしています。
以下のIssueが立っているので、「この辺が分からない」といった部分があったらコメントして下さい。
お知らせ欄
JavaScript Primerの書籍版がAmazonで購入できます。
JavaScriptに関する最新情報は週一でJSer.infoを更新しています。
GitHub Sponsorsでの支援を募集しています。