

kuromoji.jsで形態素解析した結果とテキストの関係をビジュアライズする
azu/text-map-kuromoji: テキストを形態素解析した結果とテキストの関係をビジュアライズするエディタというツールを作った話。
くだけた表現を高精度に解析するための正規化ルール自動生成手法という論文誌では、「ヵゎぃぃ」,「ゎた Uゎ」みたいな普通の形態素解析では未知語として検出されるものをどうやって正規化していくかという話が書かれていました。
これを読んでいて面白かったのは形態素解析をした結果の未知語となった部分と穴埋め的にパターンを作って、そのパターンにマッチする同じようなテキストを探すというアプローチでした。
プログラミング言語と違って、大抵の自然言語パーサはパース失敗ではなく、単なる未知な言葉として検出されます。 また、その未知な言葉は常に増えていて、さきほどのくだけた表現を高精度に解析するための正規化ルール自動生成手法によると手動では登録できない増加量らしいです。
著者らの経験では,1 人月あたり約 3 万種類の未知語登録が可 能であるのに対し,ブログ 600 万文を著名な形態素解析器 MeCab 3) を用いて解析したと ころ,約 65 万種類の未知語が検出されたことから,ブログ文書のくだけた表現を正しく解 析することは困難といえる.
この辺のスラング的な単語もクローリングしたデータから辞書を作ることで扱える量が多い辞書としてmecab-ipadic-NEologdが有名です。
で、話を戻して形態素解析をした結果の未知語となるパターンってどれぐらいあるのかなーと思いました。 普通に形態素解析した結果を見ればいいのですが、それは品詞付きの情報が並ぶだけだったり、JSONだったりして、テキストのこの部分が未知語というのがあまり見やすくはありませんでした。
今日もしないとね。
今日 名詞,副詞可能,*,*,*,*,今日,キョウ,キョー
も 助詞,係助詞,*,*,*,*,も,モ,モ
し 動詞,自立,*,*,サ変・スル,未然形,する,シ,シ
ない 助動詞,*,*,*,特殊・ナイ,基本形,ない,ナイ,ナイ
と 助詞,接続助詞,*,*,*,*,と,ト,ト
ね 助詞,終助詞,*,*,*,*,ね,ネ,ネ
。 記号,句点,*,*,*,*,。,。,。
入力されたテキストと特定の位置に関する情報をビジュアライズするパターンについてはSourceMapを調べていたときにsource-map-visualizationというサイトがあるのを思い出しました。

これの形態素解析版があると良さそうと思いました。
これの形態素解析版ほしいな "source-map-visualization" https://t.co/PZuGwXdYIQ
— azu (@azu_re) October 18, 2017
ここで、既にJavaScriptとそのパース結果からECMAScriptのバージョンをToken毎に割り出すツールを作ってたのを思い出しました。
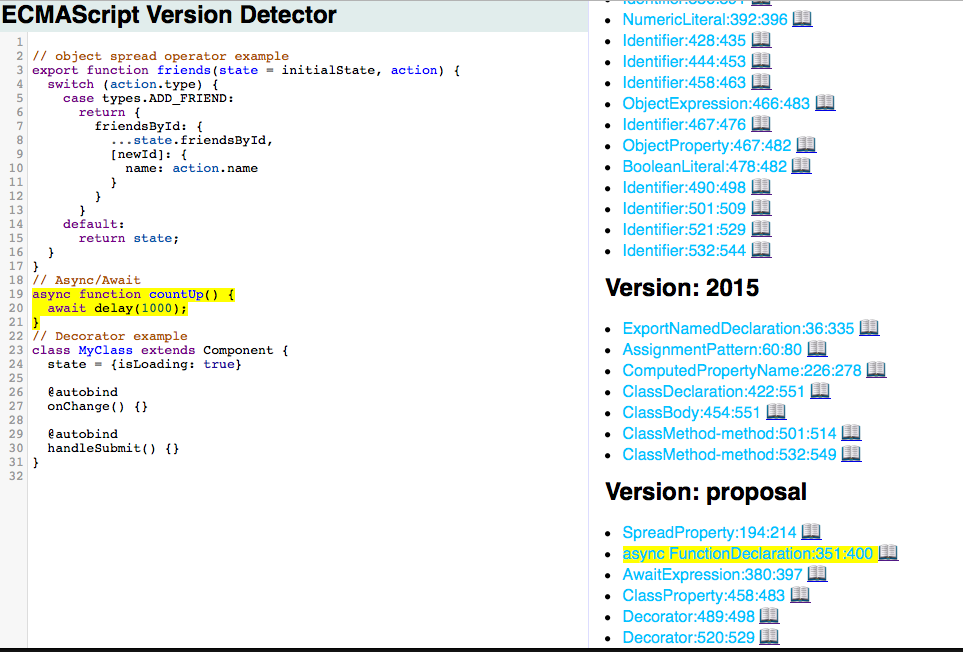
これをforkしてkuromoji.jsで形態素解析してその結果をビジュアライズするものを作りました。
https://t.co/zypZDjn20jhttps://t.co/UOhjzSxMhI
— azu (@azu_re) October 18, 2017
kuromojiで形態素解析した結果をビジュアライズするやつできた。
テキストをクリックすると対応した位置のトークン情報が表示される。 pic.twitter.com/AqrbhMJFBm
それで目的だった壊れた日本語は未知語として検出されるのかを確かめてみましたが、てにをはを間違えただけとかその程度だとやっぱり未知語として検出されないということがわかりました。
日本語の文章ってやっぱり普通に書くと未知語が結構出にくいっぽい気がする。
— azu (@azu_re) October 18, 2017
変換ミスだとアルファベットが混ざってくるので未知語 = 壊れた文章の検出ができる可能性はありそう。
壊れた日本語は検出するの難しいかもなー。パースが失敗しない問題 pic.twitter.com/EhpmHv34LD
一方、ローマ字入力のIME特有のtypoはアルファベットが不自然に混ざるからか未知な言葉として検出されやすくかったです(論文誌の形状が似てる言葉もこういうタイプ)
やっぱり形態素解析に失敗するパーサの必要性を感じました。
お知らせ欄
JavaScript Primerの書籍版がAmazonで購入できます。
JavaScriptに関する最新情報は週一でJSer.infoを更新しています。
GitHub Sponsorsでの支援を募集しています。