

モバイル/オフラインでも動作するはてなブックマーク検索のPWAを作った
はてなブックマーク検索PWAというはてなブックマークでブクマしたデータをオフラインでも検索できるPWAを作りました。
はてなブックマークの自分のブクマを検索できるPWAを作りました。
— azu (@azu_re) April 16, 2018
Service Workerに対応してるブラウザ(IOS Safari 11.3+を含む)ではオフラインでも検索できます。https://t.co/RCVkRYAFz0
モバイルはホームスクリーンアプリで、macOSはアプリ版もあります。https://t.co/5MDuyC9baN pic.twitter.com/KAc3KV690b
使い方
使い方は特に難しい話でもないですが、次のように任意のはてなブックマークのアカウント名をいれてデータを取得したら、後は絞り込み検索ができます。
- https://hatebupwa.netlify.com/ にアクセス
- 好きなはてなブックマークのアカウント名を入れて “取得”ボタンを押す
- ブックマークデータが表示されたら、フィルター検索で絞り込み
はてなブックマークの公開データを使っているので、任意のアカウントのデータを見れますが、非公開ブックマークは取得できません。
データの更新は再度画面を表示した時に自動的に行います。 能動的に更新したい場合は”取得”を再度押すか、リロードしてください。
PWA
このはてなブックマーク検索アプリはオフラインでも動作するようになっています。 他のネイティブアプリのように使いたい場合は、ホームスクリーンにアプリとして追加するかmacはアプリ版も用意しています。
- iOS: “Add to HomesScreen” on https://hatebupwa.netlify.com/
- Android: “Add to HomeScreen” on https://hatebupwa.netlify.com/
- macOS: Download from https://github.com/azu/hatebupwa/releases/latest
iOSでのホームスクリーンアプリでもオフラインで動作してる様子。 pic.twitter.com/Upu2PGpREc
— azu (@azu_re) April 16, 2018
このBaselineとしてのPWAはLighthouseや次のチェックリストが確認できます。

“Failures: Manifest start_url is not cached by a Service Worker.”
がPassできなくて100にはなってませんが実用的には問題なさそうです。 (AndroidのInstall Bannerがでなくなる気がしますが)
- Audit claims start_url of /?utm_ is not cached when navigateFallback exists · Issue #2688 · GoogleChrome/lighthouse
- Update throttling/cache/js state on the SW target · Issue #709 · GoogleChrome/lighthouse
作った理由
元々keysnailのHatebnailを使ってはてブを検索していましたが、Firefox 57+へのアップデートで拡張が使えなくなったので代わりとなるものを探しましたがなかったので作りました。 Hatebnailは旧はてなブックマーク拡張の内部的に持つデータベースを検索するため、オフラインでも高速なインクリメンタル検索ができていました。
はてなブックマーク拡張がデータの差分更新だけをやっていたので、基本的に最新のデータが手元でいつでも検索出来るような感じで使い勝手が良かったです。
はてなブックマーク検索PWAもできるだけ同じレベルで使えるように、データの更新を意識しないような作りや高速な絞り込み検索にメインにしています。
技術的詳細
ここからこのアプリの技術的なメモ書きです。
Toolkit
TypeScript + Reactで書くことにしたので、create-react-app-typescriptを使いました。 create-react-appのTypeScript版です。
今回はService WorkerやWeb Workerで少し範囲を超えた事をしないとダメでしたが、普通に使う分には面倒な設定が減るので快適です。
React 16.3 Context
このアプリを作り始めるときに最初に必要になりそうな機能やアーキテクチャをざっくりと決めていました。ついでなのでReact 16.3.0で新しくなったContext APIを試すことにしました。
このアプリはAlminというライブラリを使ってステートを管理しています。
AlminでもReact向けのbindingを公開していますが、複雑な事をするReactのHigher-Order Components(HOC)は型がとにかく複雑になりやすく、メンテナンスがしにくい問題がありました。 そのため、Render Propsと呼ばれるパターンでbindingの新しい実装を考えていましたが、Reactの新しいContext APIは一種のRender Propsパターンです。
そのため、このアプリでAlmin + React Context APIを試してみることにしました。
AlminContext.tsxにその実装を作っていて、Context.tsでReact Contextのbindingを初期化しています。
// ややこしいことにAlminにもContextがある!
import { Context, StoreGroup } from "almin";
import { UserFormContainerStore } from "./container/UserFormContainer/UserFormContainerStore";
import { SearchContainerStore } from "./container/SearchContainer/SearchContainerStore";
import { AlminLogger } from "almin-logger";
import { createContext } from "./AlminContext";
import { hatebuRepository } from "./infra/repository/HatebuRepository";
import { AppStore } from "./container/AppStore";
export const AppStoreGroup = new StoreGroup({
userFormContainer: new UserFormContainerStore({
hatebuRepository
}),
searchContainer: new SearchContainerStore({
hatebuRepository
}),
app: new AppStore()
});
export const context = new Context({
store: AppStoreGroup,
options: {
strict: false,
performanceProfile: true
}
});
// Almin + React Contextのbindingを初期化してシングルトンっぽくexportしてるだけ
const { Provider, Consumer, Subscribe } = createContext(context);
export { Provider, Consumer, Subscribe };
後は、App.tsxで各種コンポーネントを状態のオブジェクトを渡してるだけです。
render() {
return (
<>
// ... 省略 ...
<div className="App">
<h1 className={"App-title"}>
<Link href={"/"}>はてなブックマーク検索</Link>
</h1>
<!-- AlminがStateを更新検知して勝手にstateでrenderし直す -->
<Consumer>
{state => {
return (
<>
<UserFormContainer app={state.app} userFormContainer={state.userFormContainer} />
<SearchContainer searchContainer={state.searchContainer} />
</>
);
}}
</Consumer>
</div>
</>
);
}
React Context APIはコンポーネント間で値を共有する方法の一種です。
React Context APIはcreateContextで新しいコンテキストのインスタンスを作成しそれをexportするファイル作り、そのファイルをいろんなところからimportして使う形になると思います。
// some-context.js
const {Provider, Consumer} = React.createContext(defaultValue);
export {Provider, Consumer}
// app.js
import {Provider, Consumer} from "./some-context.js"
// foo.js
import {Provider, Consumer} from "./some-context.js"
一種のシングルトン的な感じになると思うので、いたるところのコンポーネントから読み込んで使うのは危険な参照になりそうです。現実的には、上の層のコンポーネント(App.jsやContainer componentなど)でContextから値を取り出し、下のプリミティブなコンポーネントには今まで通りpropsで値を渡す形に落ち着きそうな気はします。
createContextで作ったProviderとConsumerはReactコンポーネントという性質上、render()の中でしか使えません。そのためContext経由の値を他のライフサイクルイベントで使うには一度propsで渡す必要があり、Contextのみで値のやり取りが完結することは基本的にはないです。
今回はApp.tsxだけAlmin + React Contextを使って、そこから下にはpropsでアプリの状態を渡しています。
ルータ
このアプリのユースケースをalmin-usecase-map-generatorで生成すると次のような感じです。
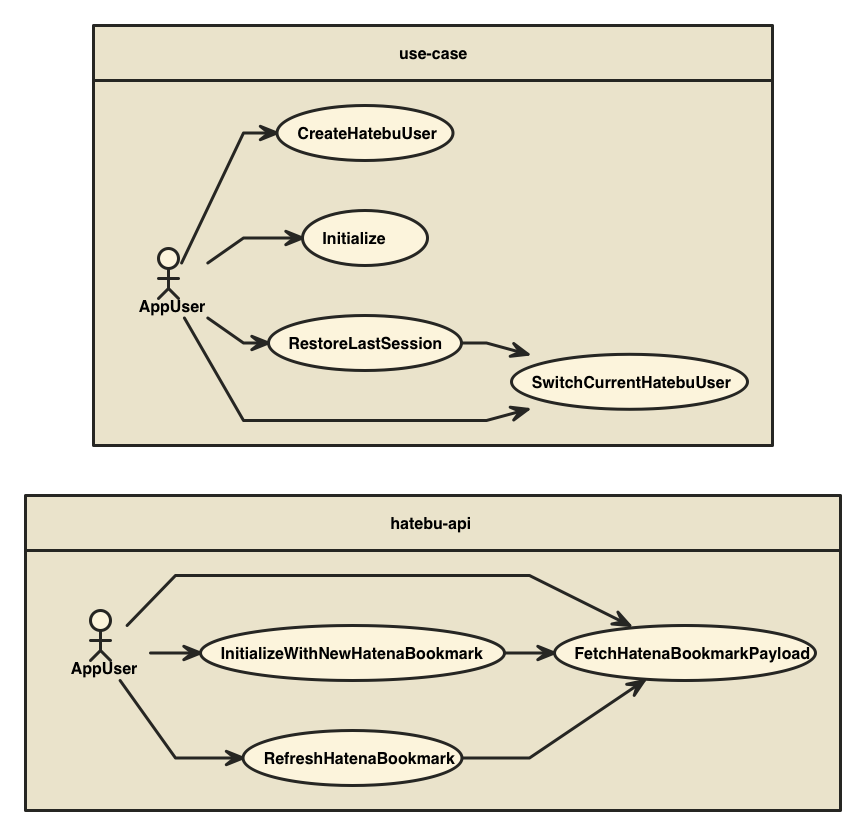
最初にInitializeSystemUseCaseを呼び、その後はURLによってどのユースケースを行うかを決めています。
Reactのルータと言えばReact RouterやUI-Router for Reactなどがありますが、URLによってコンポーネントをマウントしたいのではなく、ユースケースを呼ぶのがメインでした。 ルータがページ全体を囲むのではなく、ルータでページの一部を操作したいだけでした。 (どちらのライブラリでもできるはずですが、機能が多すぎ or 型定義が上手く合わないなどの問題があって疲れた)
色々試しているうちに面倒になってreact-routing-resolverというルーターライブラリを書き直しました。 tj/react-enrouteをコンポーネントに限定しなくした形というのが近いライブラリです。
react-routing-resolverを使いページに応じた初期化処理や特定のページだけに埋め込むコンポーネントなどを埋め込んでいます。
例えば、/user/:nameのパスに一致するページでは、this.onMatchUserを処理しつつ、PageVisibilityというページの表示状態を監視するコンポーネントを埋め込んでいます。
PageVisibilityによってページが非表示から表示に切り替わったときには、はてなブックマークからデータを取得し直すリロード処理などを行っています。
render() {
return (
<>
{this.state.isInitialized ? (
<Router history={browserHistory}>
<Route
pattern={"/user/:name"}
onMatch={this.onMatchUser}
render={(args: { name: string }) => {
return (
<PageVisibility
onVisible={() => {
this.onVisibleUserPage(args);
}}
/>
);
}}
/>
<Route pattern={"/home/"} onMatch={this.onMatchHome} />
<Route pattern={"*"} onMatch={this.onMatchOther} />
</Router>
) : null}
<div className="App">
<h1 className={"App-title"}>
<Link href={"/"}>はてなブックマーク検索</Link>
</h1>
<Consumer>
{state => {
return (
<>
<UserFormContainer app={state.app} userFormContainer={state.userFormContainer} />
<SearchContainer searchContainer={state.searchContainer} />
</>
);
}}
</Consumer>
</div>
</>
);
}
Web Worker
https://hatebupwa.netlify.com/でブックマークをフィルタ検索してみると分かりますが、ある程度のPCならある程度の量をリアルタイムにフィルターできていることがわかると思います。(Macbook Proで5万件ぐらいまでなら100ms程度で反映できる程度)
メモリ上にデータを持っているので検索自体が速いのは当然ですが、単純にUIスレッドでフィルターをするとものすごくカクつきます。 それを避けるために実際の検索キーワードでのフィルタリング処理はWeb Workerの中で行っています。
これによりかなり重たいフィルタリング処理でもUIスレッドへの影響が少なくなり、入力中の重さがかなり軽減できています。(影響が完全になくなるわけではなく、Web WorkerへpostMessageするときにデータ量が多いとそこで詰まることがある気がします)
WebWorkerを使うことでUIブロックなくせた。 pic.twitter.com/4CY95S8yA3
— azu (@azu_re) April 9, 2018
残念なことにcreate-react-appはWeb Workerをインライン化する方法がないため、Web Worker用のワーカーファイルを外部ファイルとしておいて、必要になったらアプリから読み込むようにしています。
webpackなどを使っている人はworker-loaderなどを使うことで、普通のJavaScriptモジュールと同じ感覚でWeb Workerのファイルを読み込める(インライン化できる)ので、結構気軽にWeb Workerを使えると思います。
このアプリではワーカー用のファイルとそれをビルドするwebpack.worker.config.jsをわざわざ用意してビルドするという手法を取っていますが、フィルタリングのロジック自体はワーカーとアプリで共有しています。
そのため、Workerファイル(filter.ts)に書いてあるのは10行程度のコードです。
import { HatebuSearchListItem } from "../src/container/SearchContainer/SearchContainerStore";
import { matchBookmarkItem } from "../src/domain/Hatebu/BookmarkSearch";
const registerWebworker = require("webworker-promise/lib/register");
let currentItems: HatebuSearchListItem[] = [];
registerWebworker()
.on("init", (items: HatebuSearchListItem[]) => {
currentItems = items;
})
.operation("filter", (filterWords: string[]) => {
return currentItems.filter(item => {
return matchBookmarkItem(item, filterWords);
});
});
実際のデータをTransferable ObjectsとしてWorkerに渡せると、コストがもっと減って良さそうですが、Transferable ObjectsにできるのはArrayBufferなどに限定されています。 (普通の文字列とか配列をTransferable Objectsにして転送コストを減らす方法あるのかな)
入力中のフィルタリングや補完候補を出すといった典型的な重さを感じる処理をWeb Workerに移すのは体感の改善にかなり役立つ印象です。
最初はWeb Workerに対応した検索エンジンのbvaughn/js-worker-search: JavaScript client-side search API with web-worker supportを使う予定でしたが、webworker-promiseを使って単純なArray#filterで十分でした。
webworker-promiseはWeb Workerとの間でEvent Emitter + Promiseのような感じで処理をやり取りできたので結構直感的にフィルタリング処理を書けました。 また、データを渡すイベントとフィルタリングを行うイベントを分けることで、データの転送量を減らすようにしています。
あとはIME特有のCompositionEventに対応したり、できるだけ違和感が少なく速いフィルタリング体験ができることを目標にして設計しました。
オフライン
オフライン対応するには主に2種類の対応が必要です。
- アプリのデータをストレージに持つこと
- Service Workerでリソースをキャッシュすること
前者はlocalStorageやIndexedDBなどのストレージ系のAPIを使いアプリの状態をシリアライズして保存します。容量を考えるとIndexedDBを使うのが無難です。
後者はService Workerを使いindex.htmlやjs、css、画像やフォントなどをキャッシュし、ネットワークアクセスができない状態でもページを表示するのに必要です。
Service Workerをただのキャッシュとして使うならば下手に手書きせずにWorkboxなどのフレームワークを使うのが無難です。 Service WorkerはAppCacheほどではありませんが、結構強いキャッシュです。 そのため運用や実装を間違えると面倒臭い問題があり、またデバッグも開発者ツールがないとまともにできません。
create-react-app-typescriptもsw-precacheを使ったService Workerにデフォルトで対応しています。(ただし2.0でオプトインに変わる)
ただしsw-precacheのチームは現在Workboxにリソースを割いているため、素直にWorkboxを使うことにしました。
IndexedDB
key-valueなものがあれば十分なのでlocalForageを使いました。 メモリDBへの切り替えを動的にできるラッパーとしてStorageManger.tsを作ってそれを使って、infra/repositoryでデータの永続化をしています。
(localForage以外のも探したのですが、IndexedDBに対応していて、安定していて、メモリDBなどのデバッグやテストの補助があって、key-valueでシンプルなAPIというものがなかなか見つからなかった…)
アプリとしての状態はdomainとして管理してあり、domainをシリアライズ/デシリアライズして永続化するのがinfraのrepositoryの役割です。 このアプリでは、HatebuやBookmarkといったdomainがJSONにシリアライズできるインターフェースを定義してあるので、repositoryではそれを使ってJSON化したデータをIndexedDBへ保存しています。
逆にアプリの起動時にはInitializeSystemUseCaseでrepositoyがIndexedDBからデータを取得して、それぞれのdomainを復元しています。
domain – つまりクラスのシリアライズ/デシリアライズは相変わらず難しく、Scalaなど機能が充実しているものはPlainなクラスでキレイに書けていいなと思いました。
Entityはuniqu idを持っていて、EntityをJSONにシリアライズ/JSONからデシリアライズできるインターフェースがあり、RepositoryはEntityをコレクション的に保存できて… みたいなよくあるパターンは毎回同じ事を書くのが面倒なので、ddd-baseというライブラリを書いて使っています。
ddd-baseも機能的に優れていたり洗練されているわけでもないので、ちょっとづつよくしていきたいなと思っています。 これを使うことでEntityとかRepositoryとかはある程度迷うことなく書けるようになるかなーと思います。 (シリアライズ周りは未だに書いてて若干の苦痛があるので、もう少し楽できるようになりたい。Decoratorを使わずに手軽にConverterを定義したい…)
Service Worker
アプリの状態はIndexedDBに永続化しても、ブラウザがページを表示するのに必要なのはHTMLです。 そのため、HTML自体をオフラインでアクセスできるようにキャッシュしておかないと行けません。 これを行うにはApplication CacheかService Workerが必要ですが、Application Cacheは廃止予定でありService Workerへ移行しています。(Service Worker自体がBetter AppCacheとして始まったプロジェクト)
先ほども書いたように今回はWorkboxを使いました。 Workboxのキャッシュ方法は大きく分けて、PrecacheとRuntime Cachingがあります。
今回必要なのはデプロイしたHTMLやJS、CSSなどを静的にキャッシュするように指定できるPrecacheです。workbox-cliを使うことで、インタラクティブにどのファイルをPrecacheするかを決めた設定ファイル(workbox-config.js)を作成できます。
npm install workbox-cli --global
workbox wizard
詳しくは次のページで解説されています。
後は、この設定ファイル(workbox-config.js)を元にworkbox generateSWでService Workerファイルを作成して読み込むだけです。
Service Workerでキャッシュするのは、create-react-app-typescriptでビルドしたjsなどなのでビルド後にworkbox generateSWを実行するようなnpm run-scriptsを書いています。
"scripts": {
// WebWorkerのビルド -> js,css,htmlのビルド -> ビルドしたファイルをswでキャッシュする設定を作成
"build": "npm-run-all build:worker build:react sw:generate",
"build:react": "react-scripts-ts build",
"build:worker": "webpack --mode production --config webpack.worker.config.js",
"sw:generate": "workbox generateSW workbox-config.js"
},
UI
UIフレームワークにはMicrosoftのOffice UI Fabricを使っています。
ReactのUIフレームワーク 何だかんだOffice UI Fabricがよくできてよく使ってる。 "Home - Office UI Fabric" https://t.co/8BZEHEIPdb
— azu (@azu_re) April 11, 2018
検索結果を表示するList、やたら充実しているButtonやIconsなどこういったアプリを作るには便利な機能が多いのでよく使っています。
またTypeScriptで書かれていてここ1-2年使っていますが安定して開発されていて、互換性もそこまで壊れないのでUIフレームワークとして結構気に入っています。
数人のチームとかになるとさすがにちゃんと基礎コンポーネントを作りますが、一人で作るならその辺を全部スキップできて、FocusZoneのような見えないUIもちゃんと作っているOffice UI Fabricはなかなか便利です。
まとめ
このアプリを作るにあたって最初に必要なものをバッと書き出してから作り始めました。
やってみるか pic.twitter.com/lgHqkERLJ1
— azu (@azu_re) April 7, 2018
最終的に最初のイメージとそこまでずれることなくアプリを作れてよかったです。
できたhttps://t.co/RXNLx4u3okhttps://t.co/eNogPZc9FP pic.twitter.com/SOIJbBsg0W
— azu (@azu_re) April 12, 2018
これでざっくりとしたはてなブックマーク検索PWAの紹介は終わりです。間違ってFirefoxをアップデートして必要になって突貫で作ったので、まだ微妙なところもあるかもしれません。 また遅くならないように設計しましたが、早くなるような実装はまだできていません。
そのためIssuesやPull Requestsを待っています!
作り終わってから過去にもはてなブックマーク検索ツールを書いていたことを思い出しました。
お知らせ欄
JavaScript Primerの書籍版がAmazonで購入できます。
JavaScriptに関する最新情報は週一でJSer.infoを更新しています。