

ChromeのSpeechRecognitionで使って、音声ファイルの自動文字起こしをするアプリを書いた
SpeechRecognition APIを使って、wavやmp3などの音声ファイルを再生しながら文字起こしをするウェブアプリを書きました。音声ファイルをざっくりと文字に起こして、内容をざっくりと把握して聞きたい位置にジャンプする目的で作りました。
「Chromeの」としているのは、現時点(2020-12-31)ではSpeechRecognitionを実装しているのがChrome系のブラウザのみだからです。
SpeechRecognition APIを使って音声ファイルの文字起こしをするアプリを書いた。https://t.co/GSI1gOvLVE
— azu (@azu_re) December 19, 2020
*Chrome + BlackHoleが必要
かなり無理矢理な方法でInputとOutputにBlackholeを設定して、loopbackした音声を認識させてる。 pic.twitter.com/MnZswNQhdY
必要なもの
- Chrome
- MSEdgeなどChrome系のブラウザでも大丈夫です
- BlackHole on macOS
自分はmacOSで確認しているのでBlackHoleを使っています。 BlackHoleは音声ドライバで、InputとOutputをどちらもBlackHoleに設定することで、macOSから出力した音声をmacOSで入力した音声として扱えます。
使い方
- まずは BlackHole をインストールが必要です
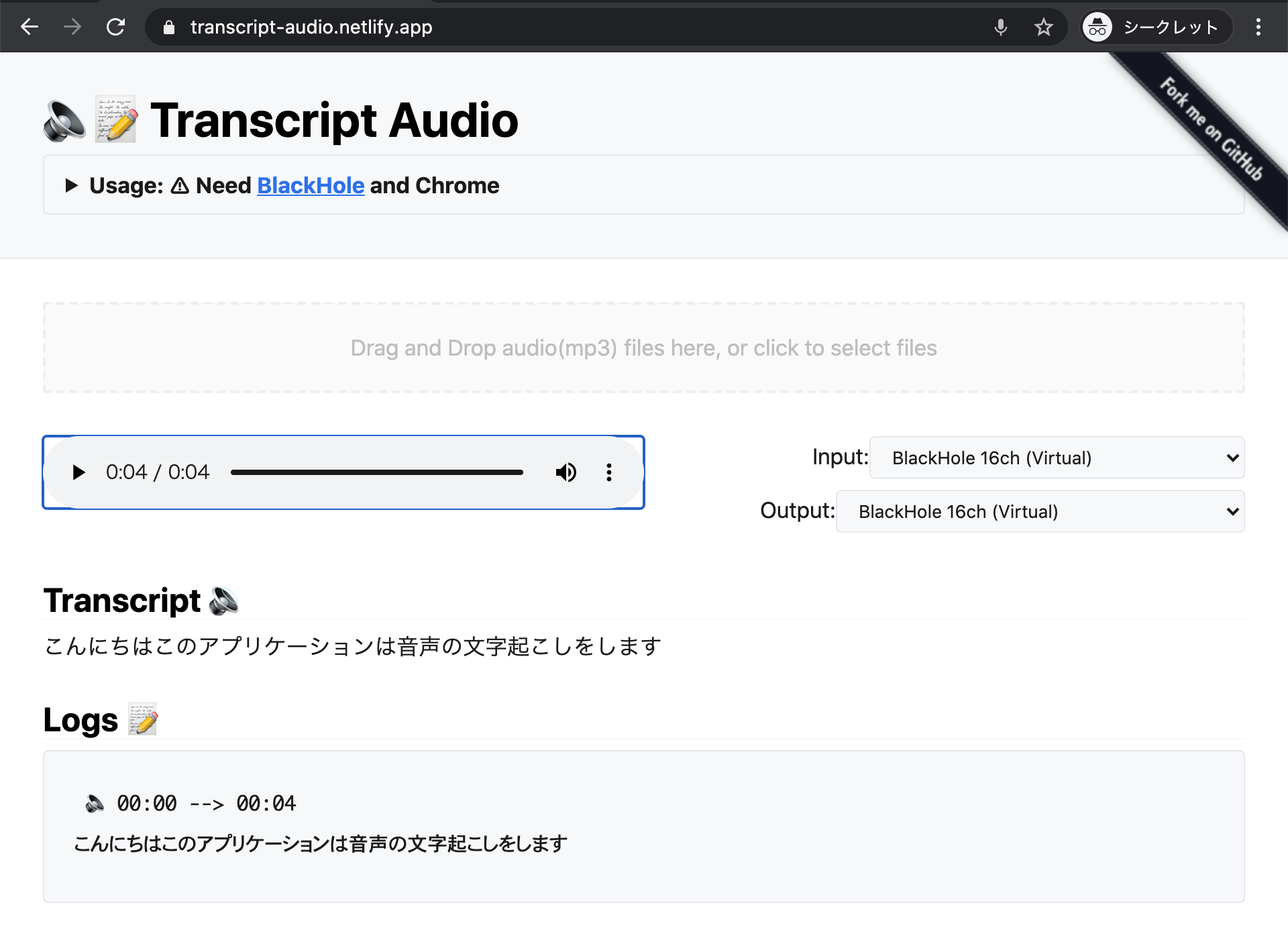
- https://transcript-audio.netlify.app/ を開く
- 最初にそのままプレイヤーの ▶ の再生ボタンを押すと、🎤マイクの許可ボタンがでるので許可します
- BlackHoleを入力音声にするためにマイクを使います。
- そして一度リロードします
- ここは実装が適当なだけなので、改善できるかもしれない
- リロード後は、文字起こししたい音声ファイルをD&Dしてください
- あとは▶ の再生ボタンを押せば、再生しながら文字起こしした内容が表示されます。
文字起こしは、実際に再生した音声をSpeechRecognitionで音声認識して文字に起こしています。 そのため、1時間の音声ファイルなら、すべて文字に起こすのに1時間かかります。
🔈 ボタンを押すと、その文字起こしをした再生位置に移動できます。
この辺の発言ってどの辺だったけというのをざっくりみて、🔈で移動して再生するみたいな用途に使えるかもしれません。
注意:
- 文字起こしされない場合は、Input/OutputがどちらもBlackHoleとなっているかをチェックしてください
- 音声が聞こえているなら、OutputがBlackHoleになていない
- また現在はlangを”ja”に固定しているので、日本語以外が認識できてないと思います。PR待ってます
仕組み
SpeechRecognition APIを触ったことがある人は、音声ファイルを認識させるという同じ発想を考えたことがあると思います。
ただし、SpeechRecognitionにはinputを指定するAPIは用意されていません。 常に現在のマイクがInputになっています。
一つのウェブページに複数のマイクは現実的にない気がしたので、navigator.mediaDevices.getUserMediaで特定のデバイスを音声の入力のデバイスに設定(ビデオ会議とかで音声デバイス切り替えするのはこのAPIを使う)してみたところ、SpeechRecognitionの入力もこの指定したデバイスになりました。
const setLoopbackAudioDevice = async (device: MediaDeviceInfo) => {
const loopbackAudioDeviceId = device.deviceId;
const constraints = {
audio: {
deviceId: loopbackAudioDeviceId
}
};
await navigator.mediaDevices.getUserMedia(constraints).then(function (stream) {
console.log("Set Loopback Audio", stream);
});
};
あとは音声を再生したAudio要素の出力先のデバイスはHTMLMediaElement.setSinkId()で指定すれば、入力と出力をどちらもBlackHoleなどのループバックデバイスに固定できます。
この状態で音声を再生すれば、自分自身が再生した音声を自分自身で認識して文字起こしが可能になります。
この入力、出力デバイスはウェブページごとの設定であるため、他のタブやmacOS自体のデフォルトデバイスを設定しなくてよいというのがこのツールの主な機能です。
PuppeteerでもChromeを使えばSpeechRecognitionは使えるので、同じような処理を書けばCLIとしてもできるのかもしれません。
- azu/convert-audio-to-text: [WIP] Convert mp3 audio to text with Puppeteer/Chrome/SpeechRecognition.
- 元々はこれで試していたもの
- OSの音声デバイス変更しないといけないのどうやって回避するんだろと思って調べたら、Transcript Audioができた
おわりに
SpeechRecognitionの仕組み的に、実際に再生している音声の文字起こしです。 文字起こしできるのは再生している部分だけなので、すべてをテキスト化する用途ではないです。
そのため、一括で大量の音声をテキスト化したい場合は、それに特化したサービスを使ったほうが良いです。 (どちらの場合もテキストを公開する場合は、元音声の持ち主の許可が必要なので注意)
(自分自身を含め)話している音声をスキップできない状態で聞くのは拘束的な感じがして苦手なので、 音声を再生しながらテキストにおこして、テキストを目で確認して🔈で実際に再生して音として確認したりそういう用途に使えるかもと思って作ってみました。
また、SpeechRecognition、VoiceIn、Speechnotes、iOSやmacOSなどの音声入力(認識)はベースとなる文章は生成できる程度にはちゃんと認識してくれます。(それ用のマイクとか喋り方などはあるだろうけど)
ただ、音声入力系は話している途中で文字としてでてくるため、文字起こしの細かい間違いが気になって喋りきることが大変な感じがしました。 一度しゃべりきった音声ファイルを再生しながら、文字起こししてしつつ修正していくのもよさそうなのかなと思いました。 このSpeechRecognitionを使った音声ファイルの文字起こしは、そういった実験にも使えそうな気がします。
ソースコード:
お知らせ欄
JavaScript Primerの書籍版がAmazonで購入できます。
JavaScriptに関する最新情報は週一でJSer.infoを更新しています。
GitHub Sponsorsでの支援を募集しています。