

自分のTweetsをインクリメンタル検索できるサービス作成キット と Tweetsをまとめて削除するツールを書いた
自分のTweetsをインクリメンタルに全文検索できるmytweetsを作りました。 また、自分のTweetsをtextlintや単語感情極性対応表や辞書ベースでフィルタリングしてまとめて削除するdelete-tweetsを作りました。
どちらもTwitterのアーカイブを使って今までのすべてのTweetsを対象にしています。 そのため、どちらも最初に次のドキュメントに従って、Twitterのデータアーカイブをダウンロードしておく必要があります。(申請から1日ぐらいかかります)
mytweets
mytweetsは、Twilogやツイセーブのように自分のTweetsの履歴を全文検索できるサイトを作るツールキットです。
Twitterのデータアーカイブをインポートするので過去全ての履歴に対応していて、 また新しいTweetsはTwitter V2 APIを使って取得する仕組みも持っています。(つまり全部のTweetsが検索できるということです)
自分のTweetsだけをインクリメンタルに検索できるサイトを作るmytweetsというツールキットを公開しました。https://t.co/1vJy6KcCcL
— azu (@azu_re) June 17, 2021
Twitterのアーカイブをインポートできるので全ての履歴を取り込めて、かつTwitter APIで差分も更新できます。
自分用Twilogを$0.Xで作るキットみたいなものです。 pic.twitter.com/VQDVQHpJBV
追記: インクリメンタル検索は、IMEが確定してから検索できるようにComposition Eventに対応しました。
仕組みとしてはS3に全てのツイートをまとめたtweets.jsonを保存し、
そのJSONファイルをS3 Selectを使って全文検索します。
S3 SelectはS3に置いてあるJSONLDやCSVのファイルに対してSQLでファイル内検索ができる仕組みです。 複数ファイルの検索はできないので、複数ファイルの場合はAmazon Athenaなどが必要です。philan.netではAthenaを使って集計しています。
検索するサイト自体は、Next.jsをserverless-next.jsを使って動かします(普通にVercelでNext.jsを動かすのも可能です。こっちをデフォルトにするかも)。 serverless-next.jsは、Cloudfront + S3 + Lambda@Edgeを使ってNext.jsを動かすServerless Frameworkのプラグインです。
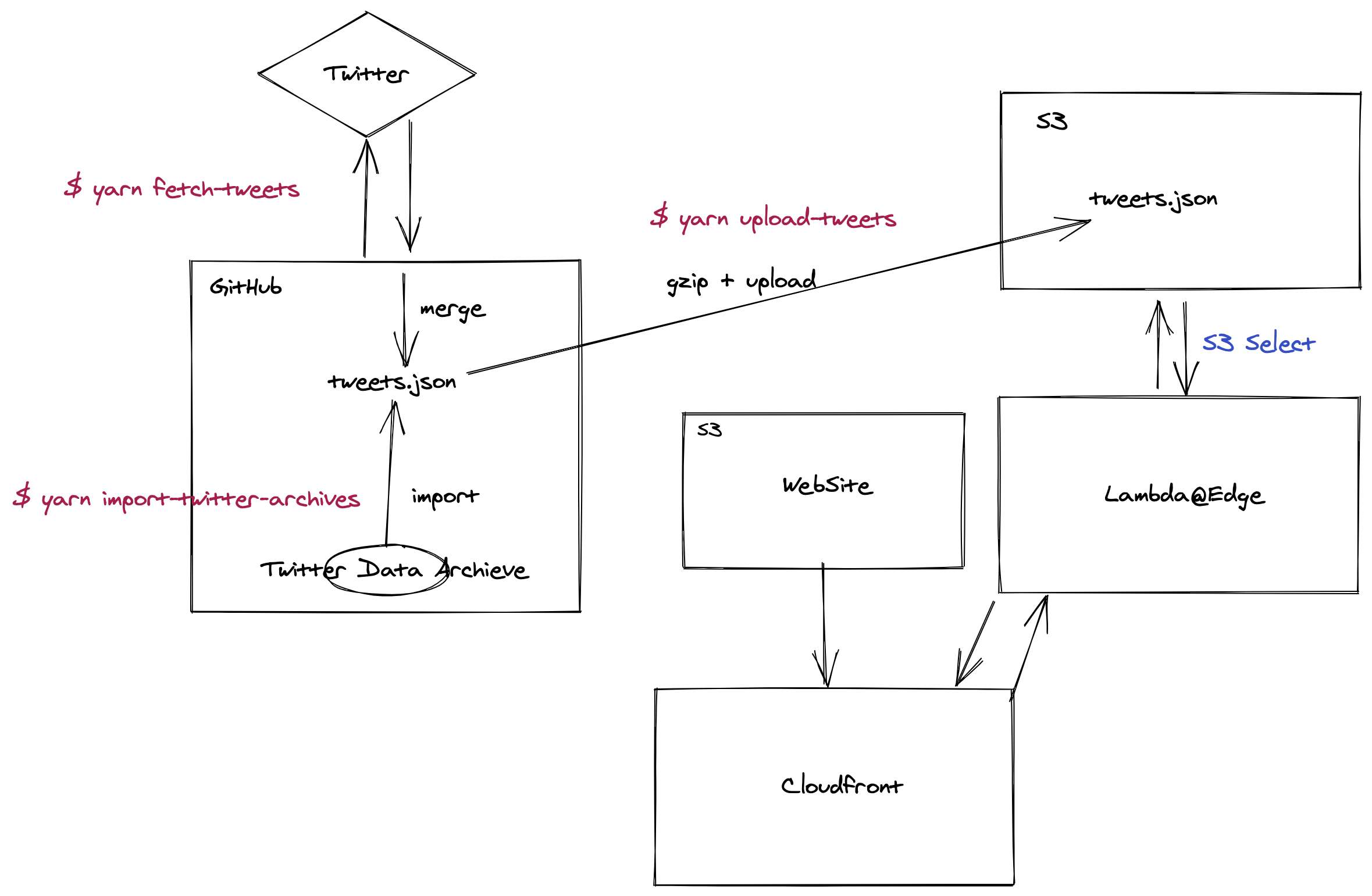
そのため、mytweetsを動かすには次のものが必要です。
tweets.jsonを保存するS3のBucket- S3のBucketを読み書きするAWSのトークン
- TwitterからTweetsを読み込むためTwitter APIトークン
これらの情報を.envファイルに渡すことで、yarn fetch-tweetsやyarn upload-tweetsなどができるようになっています。
S3_AWS_ACCESS_KEY_ID="x"
S3_AWS_SECRET_ACCESS_KEY="x"
S3_BUCKET_NAME="x"
TWITTER_APP_KEY="x"
TWITTER_APP_SECRET="x"
TWITTER_ACCESS_TOKEN="x"
TWITTER_ACCESS_SECRET="x"
詳しい使い方はREADMEを読んでください。
サイト自体はCloudfrontで公開する形になっています。(Next.jsが動けば何でもいいのでVercelなどでも問題はないです。S3に近い場所が適切) 最近追加されたCloudFront Functionsを使えばベーシック認証などもかけられるので、プライベートな検索ページも作れます。
📝 デフォルトでは中間ファイルをGitHubにも保存しているので、Privateにしたい場合はリポジトリもPrivateにしてください。
コストの方は、S3 + S3 Selectが一番かかると思いますが、月$1以下になると思います。
tweets.json のサイズ次第ですが、自分の場合30万ツイートで20MB(gzip後)なので、そこまで大きくはならない感じもします。
1週間ぐらい開発で結構S3上げ直したり、S3 Selectを叩きまくったり、Cloudfornt Functionsとかも使ったりしてるのだけど、コストはこんな感じなので、多分 $1/month いかないぐらいで動く気はします。 pic.twitter.com/BZ2O18r0Yl
— azu (@azu_re) June 17, 2021
Tweetsの差分取得は、yarn fetch-tweetsを定期的に叩ける場所なら何でも良い感じになっています。
READMEではGitHub Actionsを使ったレシピを公開しています。
mytweetsが検索する元ソースのtweets.jsonはただの行ごとのJSON(JSONLD)なので、jqで扱えたりいらないものは検索対象から外したりとか色々工夫できる気がします。
詳細はREADMEを参照してください。
delete-tweets
mytweetsを作っていたら同じような仕組みで、過去全てのTweetsを対象にしたTweetの削除ツールが書けることに気づいたのでdelete-tweetsを作りました。
mytweetsで検索するときに、べつに出てこなくてもいいTweetsも多いなと思いました。 ただ数が多いので、ある程度自動的に削除する候補を抽出できる仕組みをtextlintや感情極性値や辞書ベースで実装したのがdelete-tweetsです。 (⚠ mytweetsは、一度Twitterのデータアーカイブをインポートした部分は、その後元のTweetsを削除しても取り込んだ部分は消えないので、再インポートするなどが必要です。逆に消したTweetsも検索したいなら何もしなくても良いです)
delete-tweetsもTwitterのデータアーカイブに対応しているため、全てのTweetsが対象となっています。
delete-tweetsは次のステップで削除するTweetsを選択出来ます。
- Import Archive - TwitterのアーカイブからTweetsデータの作成
- Detect Tweets - Tweetsデータをフィルタリングして削除候補のTweetsデータを作成
- Delete Tweets - 削除対象のTweetsを削除
delete-tweetsで削除したTweetのIDはdata/deleted-twwets.txtに記録されます。
次からすでに削除済みのTweetは無視されるので、2 ~ 3 を繰り返し実行できるようにデザインしています。
2のDetect Tweetsでは次の仕組みで削除候補を抽出できるようになっています。
- 抽出する範囲を
--fromDateと--toDateで指定 - textlintでの放送禁止用語、不適切表現のチェック
- ポジティブ、ネガティブベースの推定
- 単語感情極性対応表は各自でダウンロードする形式にしています
- ユーザー定義の許可リスト、不許可リスト
⚠ 基本的に過剰に抽出するようにデザインされているので、細かいところは辞書などで調整してください。たとえば “寝る” とか 超短文なTweetsもデフォルトでは結構かかるようになってるので、その辺は調整できる人が使って下さい。 また、Tweetsの削除をすると復元はできないので、自己責任で削除してください。
delete-tweetsでもmytweetsと同じく全てのTweetsを行ごとにJSONで区切ったものを扱います。 そのため、抽出後のJSONに対してjqを使って何がかかったのか確認したり、favorites数でソートしてみたり色々できます。
delete-tweetsはwrite権限を持ったTwitter V2 APIのクライアント情報が必要になるので、詳しい使い方はRAEDMEを参照してください。
⚠ 削除の仕組み上、TwitterのAPIを大量に叩きます。0.5sごとにAPIを叩いたり、エラーがでたら自動で止まるようにしたり、エラーが起きた箇所から再開できるようにしてはいますが、削除は自己責任でお願いします。
まとめ
Twitterの自分のログをPC、モバイルどっちでもインクリメンタルに検索できるものが欲しくなったのでmytweetsを作りました。 S3 Selectは、上から順番にスキャンするという感じの予想通りな動きをしてくれて、30万ツイート(30万行)ぐらいなら1~2秒で完了するので、結構便利でした。(gzip圧縮してるとScanでRangeを指定できないのは微妙な制約だった)
LambdaだとStreamでレスポンスを上手く返せなかったので、Fetch with Streamで取得しつつ検索結果を表示というのは諦めましたが、コスパは良い感じのものができてよかった気がします。
mytweetsの仕組みを応用して、Tweetsの削除をするdelete-tweetsも作りました。 ネガティブポジティブの判定には単語感情極性対応表とnegaposi-analyzer-jaでやっていますが、ネガティブな単語のほうが辞書として多いので、普通に書くと大体0未満のスコア(ネガティブより)になると思います。 「寝る」とか単語一つみたいなものとかもそういう事情でかかりやすいですが、こういうTweetsは検索結果にでてきてもあまり意味はないので、デフォルトでは検出されるようになっています。
delete-tweetsは機械的にやるだけの仕組みなので、ちゃんとやりたい人は外部サービスを使うのがよさそうです。 TwitterのAPIには3200件までしか遡れないという制限があるので、外部サービスを使う場合もTwitterのデータアーカイブが必要になります。
お知らせ欄
JavaScript Primerの書籍版がAmazonで購入できます。
JavaScriptに関する最新情報は週一でJSer.infoを更新しています。
GitHub Sponsorsでの支援を募集しています。