

textlintでセンテンスを扱うルールの書き方
読みやすい文章を書くためには、文(センテンス)の長さを意識する必要があります。 1文が長いと読みにくくなる傾向があるため、1文を一定の長さ以下にすることが推奨されています。
たとえば、上記の記事では、文の長さを意識するために、1文の長さを50文字や100文字以下にすることを推奨していますが、 これは、1文1文が長すぎると、1文の中に色々なことが書かれてしまい、この文のように何を言いたのかわかりにくくなるためです。
そのため、1文の長さを制限することで、それぞれの文の主張が明確になり、読みやすくなります。 textlintでは、次のルールで1文の長さを制限することができます。
1文の長さだけではなく、1文内にある読点(、)の数も意識することで、読みやすさを向上させることができます。
1文に、の数が多いと、その文の主張が複雑になりやすいため、読みにくくなります。
textlintでは、次のルールで1文の、や,の数を制限することができます。
その他にも、1文を扱うルールは色々とあります。
- textlint-ja/textlint-rule-no-doubled-joshi: 文中に同じ助詞が複数出てくるのをチェックするtextlintルール
- textlint-ja/textlint-rule-no-doubled-conjunctive-particle-ga: textlint rule plugin to check duplicated conjunctive particle
gain a sentence. - textlint-rule/textlint-rule-no-start-duplicated-conjunction: textlint rule that check no start with duplicated conjunction.
- textlint-rule/textlint-rule-en-max-word-count: textlint rule that specify the maximum word count of a sentence.
- textlint-ja/textlint-rule-no-doubled-conjunction: textlint plugin to check duplicated same conjunctions.
この記事では、“1つの文”(1つのセンテンス)を扱うtextlintのルールをどう書くのかを紹介します。
文、センテンスとは
textlintでは、MarkdownやHTMLなどのテキストをパースして、AST(抽象構文木)を作ります。
ASTは、Nodeというオブジェクトの集合体で、Nodeは親子関係を持っていてASTを構築しています。
ASTには色々なNodeがありますが、文章のテキストはパラグラフに分解してParagraph nodeになります。
たとえば、次のようなテキストをパースすると、できるのは1つのParagraph nodeです。
This is first line.
This is second line.
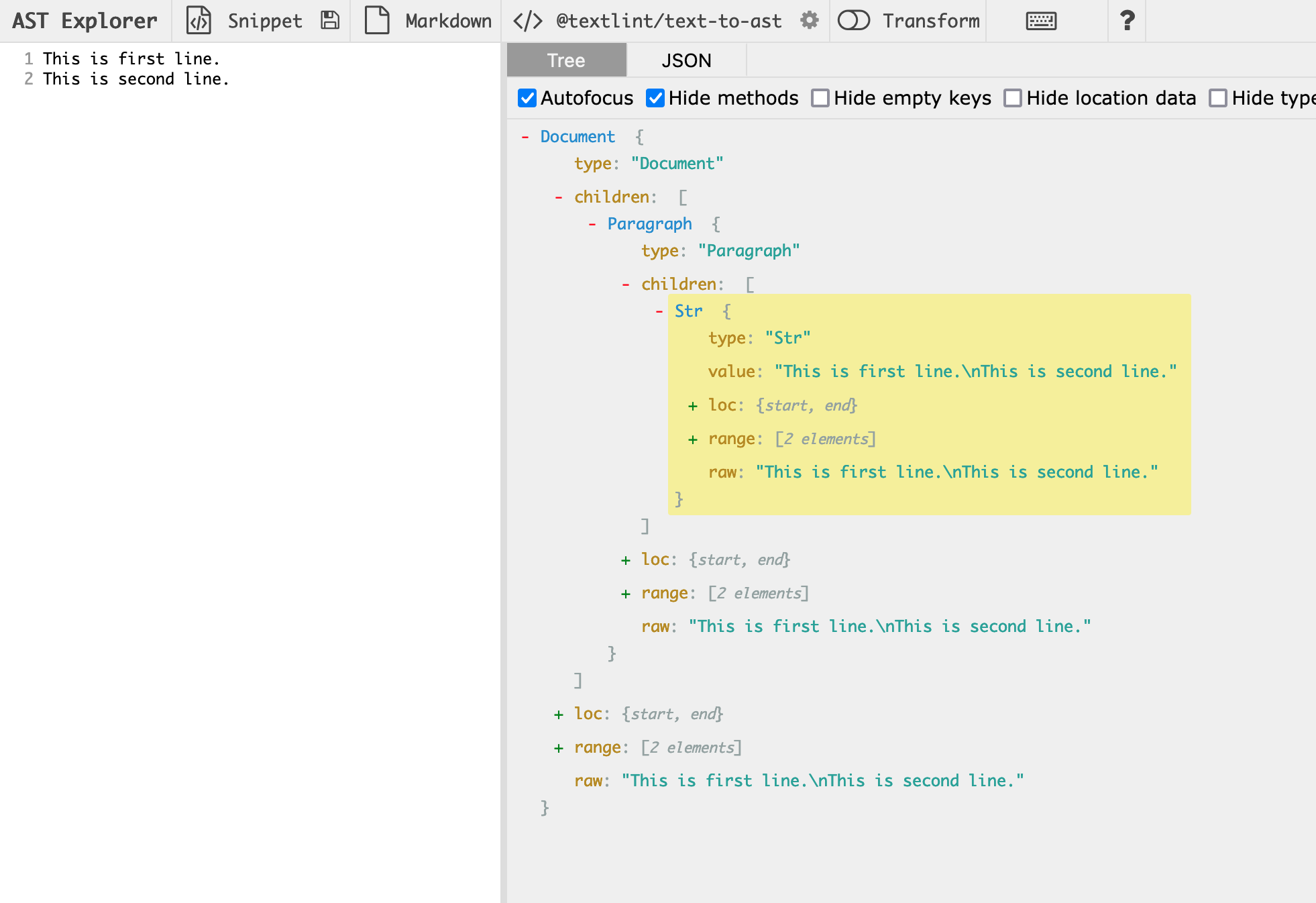
textlint AST explorerを使うと、実際にASTを確認できます。
これからもわかるように、textlint自体はパラグラフまでのパースしか行いません。 文やセンテンスといったように言葉が異なる違うことからも分かりますが、言語によって異なる可能性があるためです。
パラグラフはHTMLの<p>相当で、多くのマークアップ言語がサポートしているため、textlintも扱っています。
一方で、HTMLにはセンテンスに相当するタグはないので、書かれている自然言語によって解釈は異なる可能性があります。
textlintはあらゆる自然言語を扱えるようにするため、本体にはセンテンスの情報はありません。
textlintについては、次のスライドを参照してください。
では、どうやってセンテンスを取り出すかというと多くのルールはsentence-splitterというライブラリを利用しています。 このライブラリは、自然言語をパースしてセンテンスを取り出すためのライブラリです。 主に、英語と日本語を想定して作成しています。
sentence-splitterは、次のような1つのパラグラフを複数のセンテンスに分割します。
We are talking about pens.
He said "This is a pen. I like it".
I could relate to that statement.

この例文では、3つのセンテンスにパースして、それをASTとして返します。
2行目のセンテンスは、"で囲まれているため、2行目全体で1つのセンテンスとして扱っています。
(この"に囲まれている位置情報もcontextsという形でASTに含まれています)
- Sentence SplitterのAST: https://sentence-splitter.netlify.app/#We%20are%20talking%20about%20pens.%0AHe%20said%20%22This%20is%20a%20pen.%20I%20like%20it%22.%0AI%20could%20relate%20to%20that%20statement.
split()とsplitAST()という2つのパースメソッドを提供しています。
split(text)はテキストからASTを作成するメソッドです。
もう一方のsplitAST(ast)は、textlintのParagraph node内をパースして、センテンス情報を追加したParagraph nodeを返します。
基本的には、元のASTの位置情報(Pargraph nodeは何行目から何行目までかなど)を保持したまま、センテンス情報を取得できるsplitAST(ast)を利用します。
実際にどう使うかをみていきます。
textlint-rule-max-commaの実装
textlint-rule-max-commaは、1つのセンテンスに含まれる,の数を制限するルールです。
デフォルトでは、1つのセンテンスに含まれる,は3つまでに制限しています。
- Note: textlintのルールを全く触ったことない人は、Creating Rules · textlintを参照してください。
実装を見てみると、sentence-splitterなどのライブラリを使っているので比較的シンプルです。
大きく分けると次のような処理をしています。
- Paragraph nodeを受け取り、sentence-splitterでセンテンス情報を追加したASTを取得する
- センテンスノードからテキストを取得する
- TxtASTを含むASTから、視覚的なテキストを取得するにはtextlint-util-to-stringを使います
- たとえば
[text](http://example.com)はソースコードでは色々な記号がありますが、表示されるのはtextのみです - textlint-util-to-stringは、ASTから表示されるテキストを取得するためのユーティリティです
- センテンスごとのテキストに含まれる
,の数を数える ,の数が許容範囲を超えていたらエラーを報告する
import { splitAST, SentenceSplitterSyntax } from "sentence-splitter";
import { StringSource } from "textlint-util-to-string"
function countOfComma(text) {
return text.split(",").length - 1;
}
const defaultOptions = {
// default: allowed command count
max: 4
};
export default function (context, options = defaultOptions) {
const maxComma = options.max || defaultOptions.max;
const { Syntax, RuleError, report, locator } = context;
return {
// textlintがパースしたParagraph nodeを受け取る
[Syntax.Paragraph](node) {
// ASTをパースして、センテンス情報を追加したASTを取得する
const paragraphSentence = splitAST(node)
// センテンスノードのみを取り出す
const sentences = paragraphSentence.children.filter(node => node.type === SentenceSplitterSyntax.Sentence);
// センテンスごとにチェックしていく
sentences.forEach(sentence => {
// センテンスからCode nodeをマスキングしてから、センテンスをテキスト(表示と一致するテキスト)に変換する
// マスキングするのは `sum(0,1,2,3,4,5,6,7,8,9,10)` のようなコードはカンマを含むが、問題ないため
// マスキングすると `______________________` のようなコードになる
const source = new StringSource(sentence, {
replacer: ({ node, maskValue }) => {
if (node.type === Syntax.Code) {
return maskValue("_");
}
}
});
// センテンスのテキスト化
const sentenceValue = source.toString();
// テキストの , の数を数える
const count = countOfComma(sentenceValue);
// 最大値を超えていたらエラーを報告する
if (count > maxComma) {
const lastCommandIndex = sentenceValue.lastIndexOf(",");
report(node, new RuleError(`This sentence exceeds the maximum count of comma. Maximum is ${maxComma}.`, {
padding: locator.at(source.originalIndexFromIndex(lastCommandIndex))
}));
}
});
}
}
}
textlintはESLintなどと同じように文字列のテキストではなく、パースしたAST(オブジェクト)を扱ってLintします。 単純な文字列としてテキストを扱うと、マークアップ言語に含まれる記号などを誤検知してしまいます。(スペルチェッカーが意味ないところに赤線を引く現象の原因です)
文やセンテンスなどは、ルールを書くときに扱うことが多いので、textlintにはそれらを扱うためのライブラリが用意されています。
- sentence-splitter
- textlint-util-to-string
- その他: https://github.com/textlint/textlint/wiki/Collection-of-textlint-rule#rule-libraries
是非色々なルールを作ってみてください。
お知らせ欄
JavaScript Primerの書籍版がAmazonで購入できます。
JavaScriptに関する最新情報は週一でJSer.infoを更新しています。
GitHub Sponsorsでの支援を募集しています。