

superwhisperでの音声入力を試す
superwhisperという、whisper.cppを使った音声入力ができるmacOSアプリケーションを最近使っています。 基本的にはggerganov/whisper.cppのモデルを使って、音声認識しながら文字入力ができるアプリケーションです。
特徴
- Whisperの認識精度が高い
- かなり早く喋っても認識してくれる
- 日本語も認識してくれるモデルがある
- 日本語で喋って英語に翻訳してくれる機能もある
- オフライン対応
- 有料: サブスク と 買い切り の2種類のプランがある
- 無料で15分のトライアル、その後は選べるモデルが制限される
公式サイトのデモをみると、かなり早く喋っても認識してくれるのがわかります。 大抵の人にとっては、多分文字入力するよりしゃべったほうが早いぐらいの入力速度が出ると思います。
長文はそこまで得意じゃないけど、1行とか2行ぐらいの文章はかなり早く入力できるんじゃないかなって気がします。 句読点とかは勝手に入れてくれるので、適当にしゃべっても、ある程度文章っぽい文章になると思います。
認識の精度はMacBook Airの本体のマイクを使っても普通に認識してくれます。 それでいて、間違いもそこまで多くないのでかなり実用的です。(単語とかはたまに怪しいが文字列置換機能を辞書的に使える)
大体1-2行のテキストだとMacBook Air M2で2~3秒ぐらいの認識速度です。 文章の量が多くなるほど、認識時間が長くなるのでこの辺はまだ長文に向いてないのかなという印象です。 (Realtimeモードがあるので、この辺はインクリメンタルな結果を合成すればかなり早くなりそうな気はします)
使い方
基本的には、superwhisperのサイトからダウンロードして、起動するだけです。 使い方は単純で、使いたいモデルを選択して、起動すると音声認識が始まるので喋るだけです。
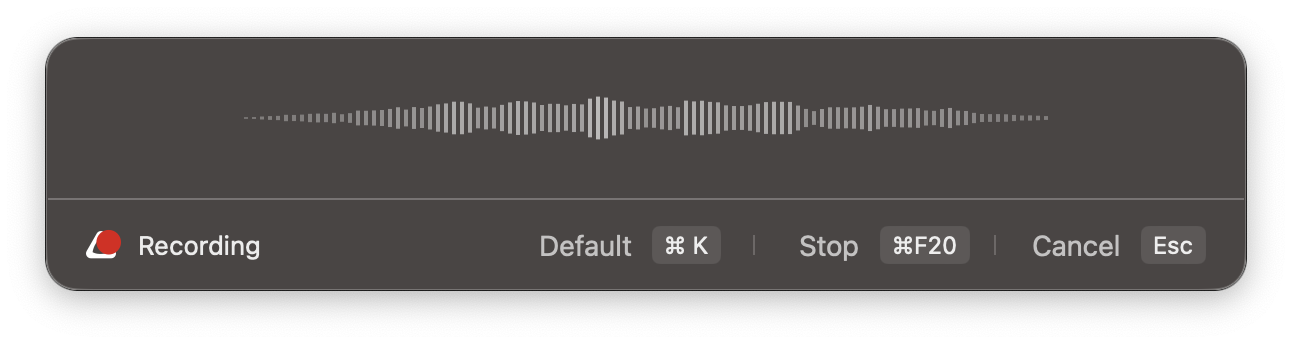
認識した結果はクリップボードにコピーするか、そのままペーストするか、実験的な機能としては文字入力を再現する機能もあります。
設定は、認識するモデルや喋る言語、認識した結果を英語に翻訳するかなどが選べます。 またリアルタイムでその認識した結果を出してくれるか、とかいう設定があります。
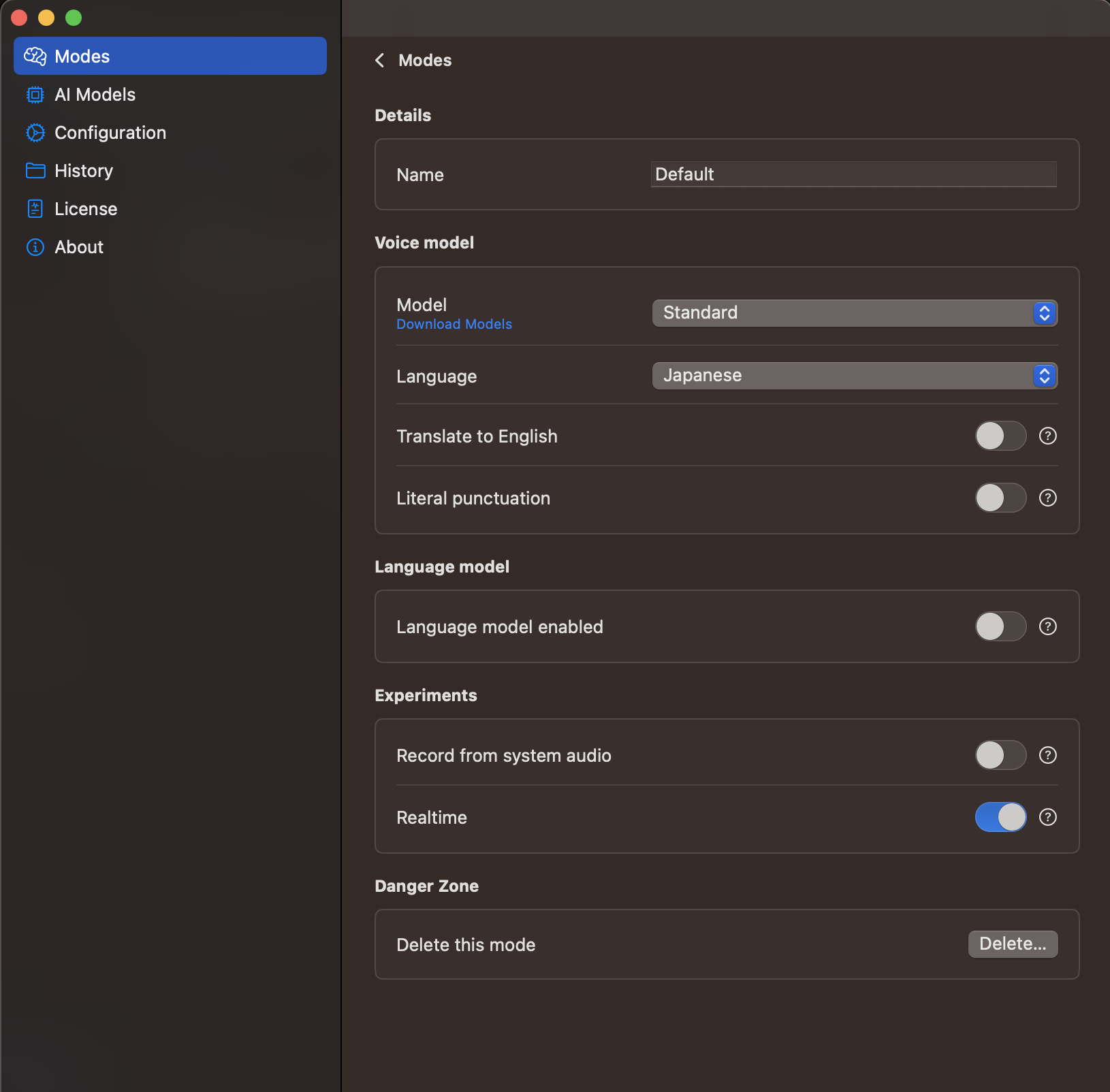
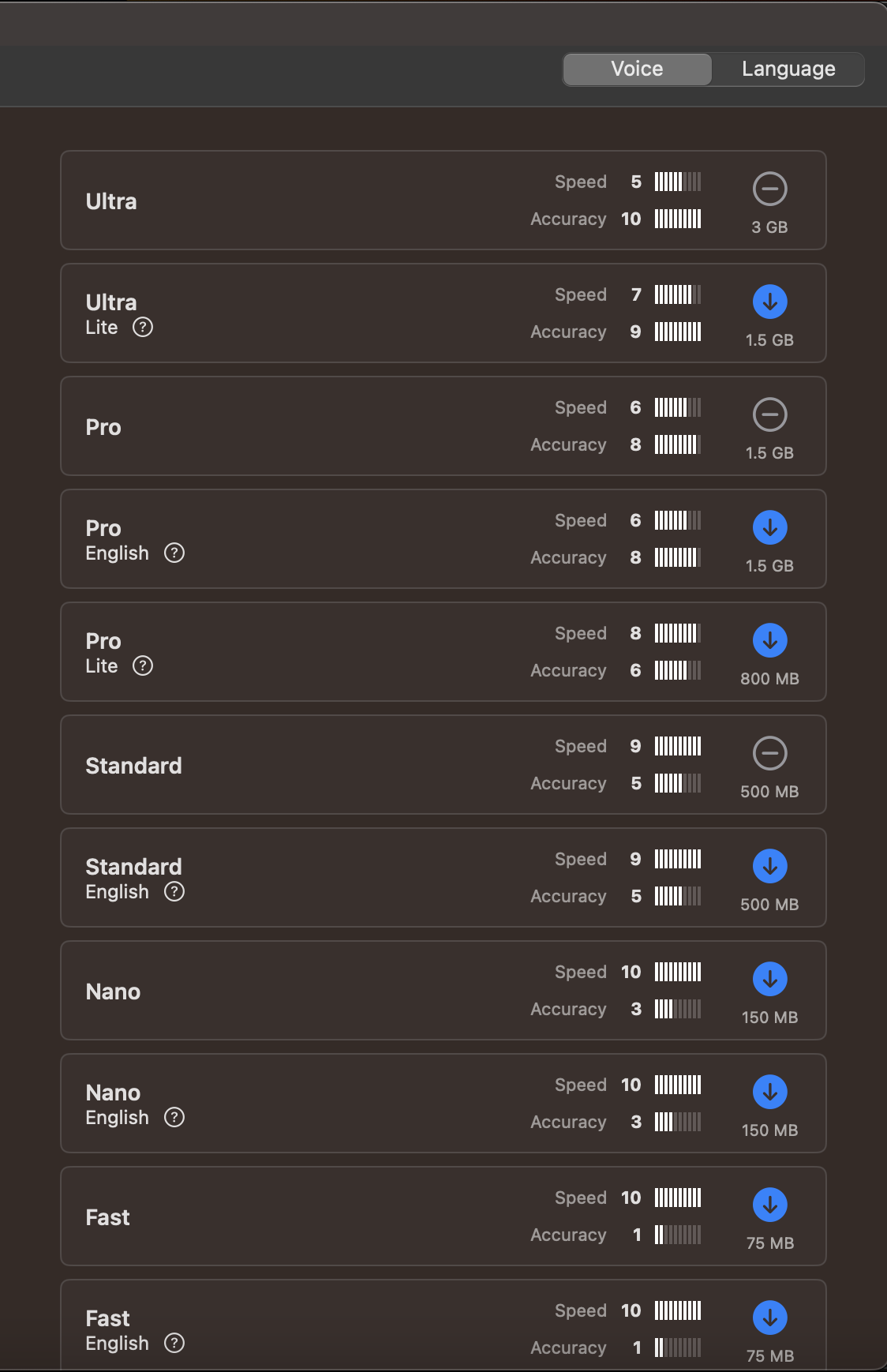
モデルはWisperのモデルを使っているので、基本的に認識精度とその認識した結果を変換する時間とのトレードオフでモデルを選ぶ感じです。
大体の人はProのモデルを選ぶのがいいと思います。
設定自体は複数作れます。 自分の場合は、日本語で喋って日本語で出力するやつ と 日本語で喋って英語で出力するやつを作成しています。
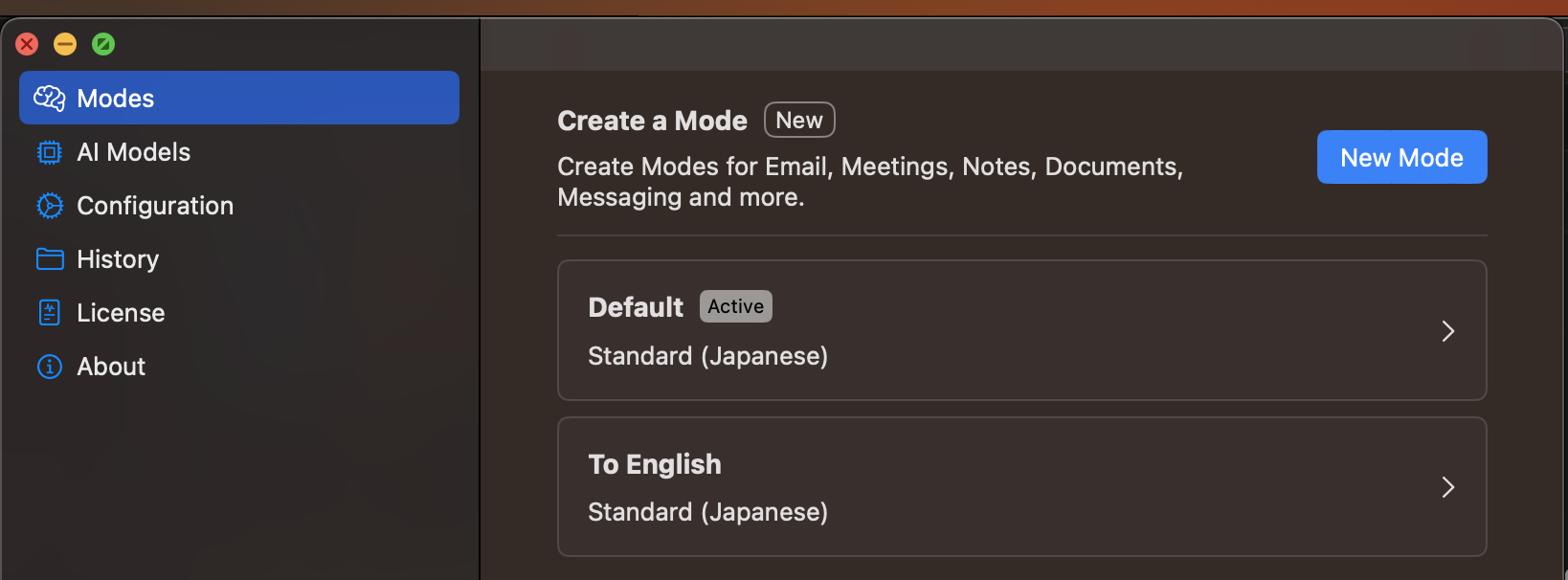
この設定は入力中に切り替えることができます。
ユースケース
音声入力と操作が同時にできる
Macの音声入力とは違って、音声の認識と操作が同時に行えます。
この特性を利用すると、喋りながらその結果を貼り付ける場所を探すという操作ができます。 大抵の音声認識だと、まずテキストフィールドを探してフォーカスを当ててから喋るというステップになります。 また、しゃべってる最中に他の操作ができなくなります。
Superwhisperは、これを無視できるのがかなり面白いところです。 たとえば、喋りながら、Twitterを開いて、その結果を貼り付けるという操作ができます。
自分の場合は、サイトをブックマークするときにメモを書くのですが、サイトとメモ欄を行ったり来たりするのが結構面倒でした。 このケースでは、Superwhisperを起動して、サイトを見ながらメモを話すことで、コンテキストを切り替えなくても良くなるような気がしています。 今は、長時間の録音や無音区間の問題があるので、そこまでできてないですが、この辺が解決できるとかなり便利になりそうな気がします。
気軽なメモとして使う
superwhisperの結果は、自動的にHistoryに追加されます。
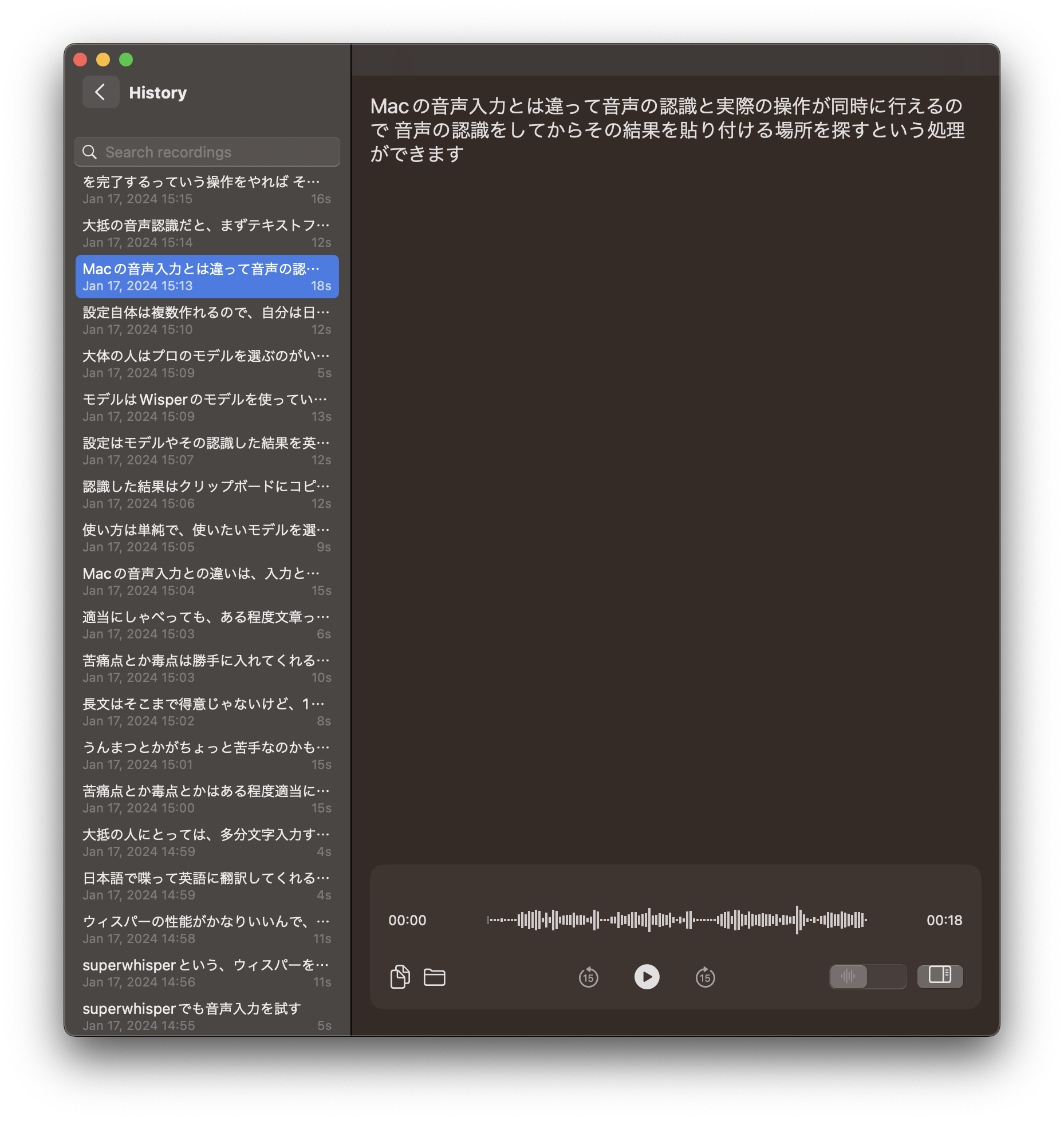
また、superwhisperの結果は~/Documents/superwhisper/recordings/にtxtとjsonとwavファイルが保存されます。
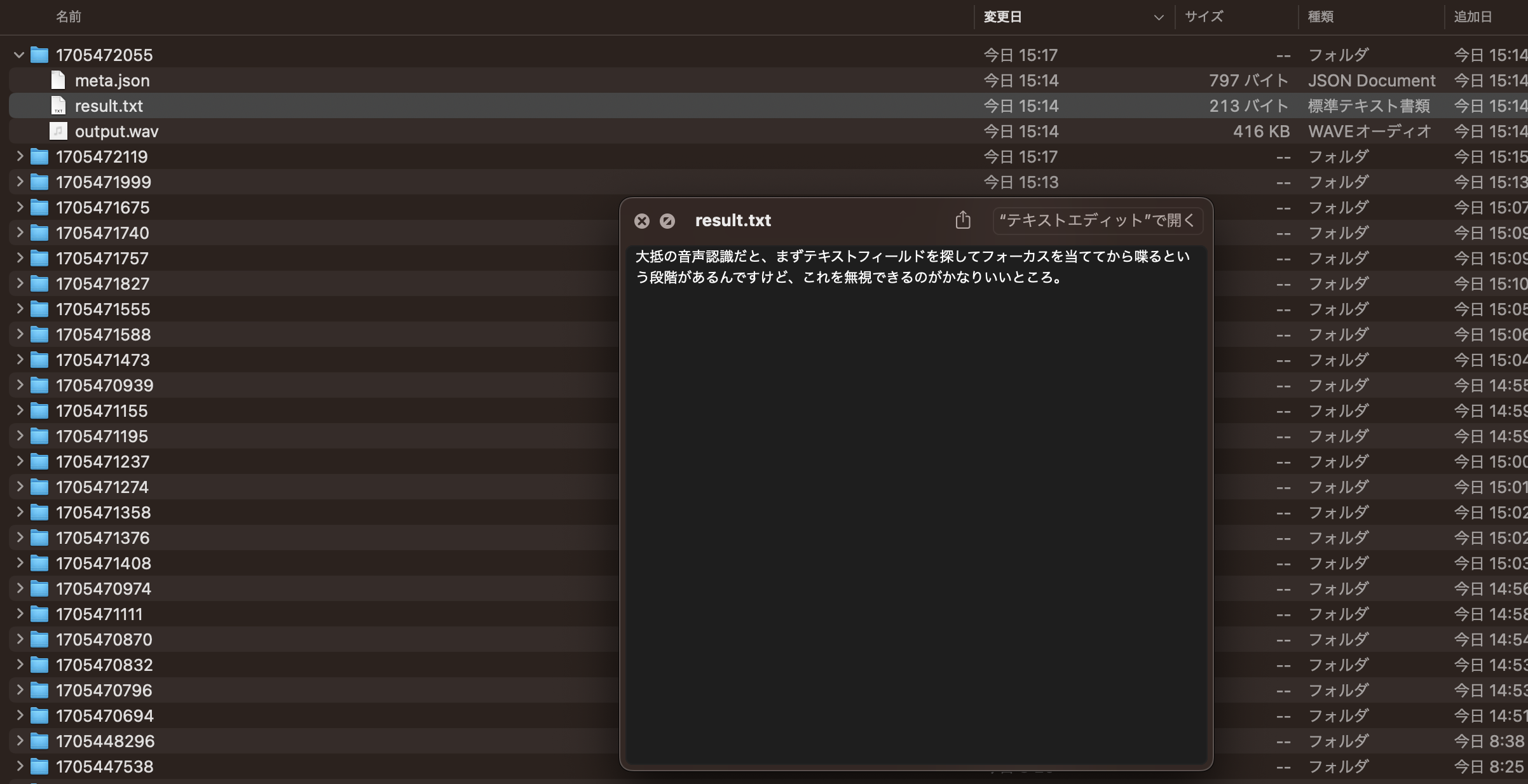
これを使うと、簡単なメモとして使うことができます。
ファイルの変更を監視すれば良い感じに使えそうな気がします。
作業ログとして使う
自分の場合は作業ログをNotionに書くようにしてるのですが、このログをsuperwhisperとショートカット.appで追加できるようにしています。
ショートキーでどこからでもメモを取って作業ログに追加できるようになった。
— azu (@azu_re) January 16, 2024
ショートカット.app の複数行入力を使えるのが結構便利だ。 pic.twitter.com/G9fDRXBCE0
Macの「ショートカット」では複数行の入力ができるテキストフィールドが作れるので、フィールドを出してそこにSuperwhisperで入力して、あとはその内容を独自のスクリプトを使ってNotionに追加しています。
日本語で喋って英語を書く
superwhisperには日本語とかで入力して、その結果を英語に翻訳する機能があります。
SuperWhisper has a function to translate the result into English by typing in Japanese.
この機能を使うと、細かい単語の修正は必要ですが、英文はある程度書けます。 GitHubとかで適当なコメントを返すのに、この機能を使うとかなり楽になりました。
その出力された内容をGoogle翻訳(QuickWebViewで表示してる)とかで日本語にして、ある程度正しいかを判断すればいいので、そんな考えなくても書けるようになったのがいいところです。 わざわざDeepLとかGrammerlyとかのサイトに行かなくても良くなります。
これによって、かなりコンテキストスイッチが減る感じで、気軽にコメントできるようになるのが良いところなのかなと思います。 GitHubではPlain English的な簡単な英語しか書かないので、シンプルに短くしゃべればシンプルな英語が出てきます。 細かい単語は専門用語とかなので、そこだけ直すイメージでやると結構スムーズです。
コマンドラインなどからSuperwhisperを起動する
superwhisper://record というURLスキームでSuperwhisperの音声認識を開始できます。
これを使うと、openコマンドなどからSuperwhisperの音声認識を開始できます。
open superwhisper://record
また、Alfred、RaycastからこのURLスキーマは利用できます。 他にも入力中にモード(設定)を切り替えられるのですが、これに対応するURLスキーマもあります。
自分の場合は、Karabiner-ElementsでFnキーを押すとSuperwhisperを起動するようにしています。
先ほどの作業ログも余ってるF<num>キーとかで起動できるようにしています。
まとめ
superwhisperは音声認識の精度がよく、かなり使いやすいです。 個人的には入力と操作を切り離せるのが かなり面白いところだなと思っています。 音声認識はそこまで厳密な精度がいるものじゃなくて、どっちかというと入力速度とか気軽さの方が大事だと思ってます。 その辺をフリーハンドにできるのがいいところかなと思っています。
iOSのSiriは速度も精度(スペルチェックと組み合わせる)もかなり良かったりします。 音声認識を試したことがない人は、一度遊んでみると面白いと思います。
音声操作はTalonとか別のアプローチがあるので、その辺はまた別の方法になっていくのかなと思っています。
この記事は8割ぐらいはsuperwhisperで喋って、ちょこちょこ手直しながら書きました。 個人的には長文よりはメモ的なスニペットを喋る感じで使うのが今のところ向いてるんじゃないかなという気がします。 SuperwhisperにはLLMのモデルを使って認識した結果を補正をするような実装も入っているんですけど、それはまだあまり実用的じゃなかったです。
文字起こし的な用途ならWhisperを使う別のツールを使い分けるとかをした方がいいと思います。 superwhisperの良い部分はInput Methodの再開発だと思っています。
💡 Tips:
Superwhisperには15分の無料期間がありますが、それを使い切ると25%オフのクーポンが出てきます。
お知らせ欄
JavaScript Primerの書籍版がAmazonで購入できます。
JavaScriptに関する最新情報は週一でJSer.infoを更新しています。
GitHub Sponsorsでの支援を募集しています。